Best Engineering Practices#



𝗔𝘁𝘁𝗿𝗶𝗯𝘂𝘁𝗶𝗼𝗻: Notes for Module 6 of the MLOps Zoomcamp (2022) by DataTalks.Club.
Introduction#
In this module, we will cover best practices for developing and deploying our code. We will take our example streaming code from a previous module, break it down into testable units, and generally just improve it with software engineering best practices.
More precisely, we create and automate unit and integration testing, code quality checks, and add pre-commit hooks for all of these. We will also look at how to use make which is a nice tools for abstracting and automating repetitive but involved tasks.
Testing Python code with pytest#
Let us look at the streaming module that we will work on:
import os
import json
import boto3
import base64
import mlflow
# Load environmental variables
PREDICTIONS_STREAM_NAME = os.getenv('PREDICTIONS_STREAM_NAME', 'ride_predictions')
RUN_ID = os.getenv('RUN_ID')
TEST_RUN = os.getenv('TEST_RUN', 'False') == 'True'
# Load model from S3
logged_model = f's3://mlflow-models-ron/1/{RUN_ID}/artifacts/model'
model = mlflow.pyfunc.load_model(logged_model)
def prepare_features(ride):
features = {}
features['PU_DO'] = '%s_%s' % (ride['PULocationID'], ride['DOLocationID'])
features['trip_distance'] = ride['trip_distance']
return features
def predict(features):
pred = model.predict(features)
return float(pred[0])
def lambda_handler(event, context):
predictions_events = []
for record in event['Records']:
encoded_data = record['kinesis']['data']
decoded_data = base64.b64decode(encoded_data).decode('utf-8')
ride_event = json.loads(decoded_data)
ride = ride_event['ride']
ride_id = ride_event['ride_id']
features = prepare_features(ride)
prediction = predict(features)
prediction_event = {
'model': 'ride_duration_prediction_model',
'version': '123',
'prediction': {
'ride_duration': prediction,
'ride_id': ride_id
}
}
if not TEST_RUN:
kinesis_client = boto3.client('kinesis')
kinesis_client.put_record(
StreamName=PREDICTIONS_STREAM_NAME,
Data=json.dumps(prediction_event),
PartitionKey=str(ride_id)
)
predictions_events.append(prediction_event)
return {
'predictions': predictions_events
}
To review, first this script loads the environmental variables and the model from S3. Then, it defines two helper functions for preprocessing and making prediction with the model. The most important function in this script is lambda_handler which takes in an event which contains a batch of events from the input stream. This explains the outer loop over event['Records'].
Inside this block, the data is decoded and a prediction is made which is packaged as an event for the output stream. If this function is in production, i.e. outside of a test run, then the prediction event is written on the output stream. In this case, a Kinesis client is instantiated, and an output event is written to the specific predictions stream.
Adding unit tests#
First, we will create a tests/ folder where we will put all our tests. We will be using pipenv to manage our environment. See the previous module for details. We will start with the following Pipfile:
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
boto3 = "*"
mlflow = "*"
scikit-learn = "==1.0.2"
[dev-packages]
pytest = "*"
[requires]
python_version = "3.9"
Notice that this installs pytest as a dev dependency. Let us create one test:
# tests/model_test.py
import lambda_function
def test_prepare_features():
"""Test preprocessing."""
ride = {
"PULocationID": 130,
"DOLocationID": 205,
"trip_distance": 3.66
}
actual_features = lambda_function.prepare_features(ride)
expected_features = {
'PU_DO': '130_205',
'trip_distance': 3.66,
}
assert actual_features == expected_features
Before running this, since this test is not related to the model, we can comment out the block that loads the model from S3 to make this test run faster. Tests can be run either by doing $ pytest on the terminal:
$ pytest
======================== test session starts ========================
platform darwin -- Python 3.9.12, pytest-7.1.2, pluggy-1.0.0
rootdir: /Users/particle1331/code/ok-transformer/docs/nb/mlops/06-best-practices
plugins: anyio-3.6.1
collected 1 item
tests/model_test.py . [100%]
========================= 1 passed in 1.03s =========================
Or using the UI in VS Code after selecting pytest in the configuration:
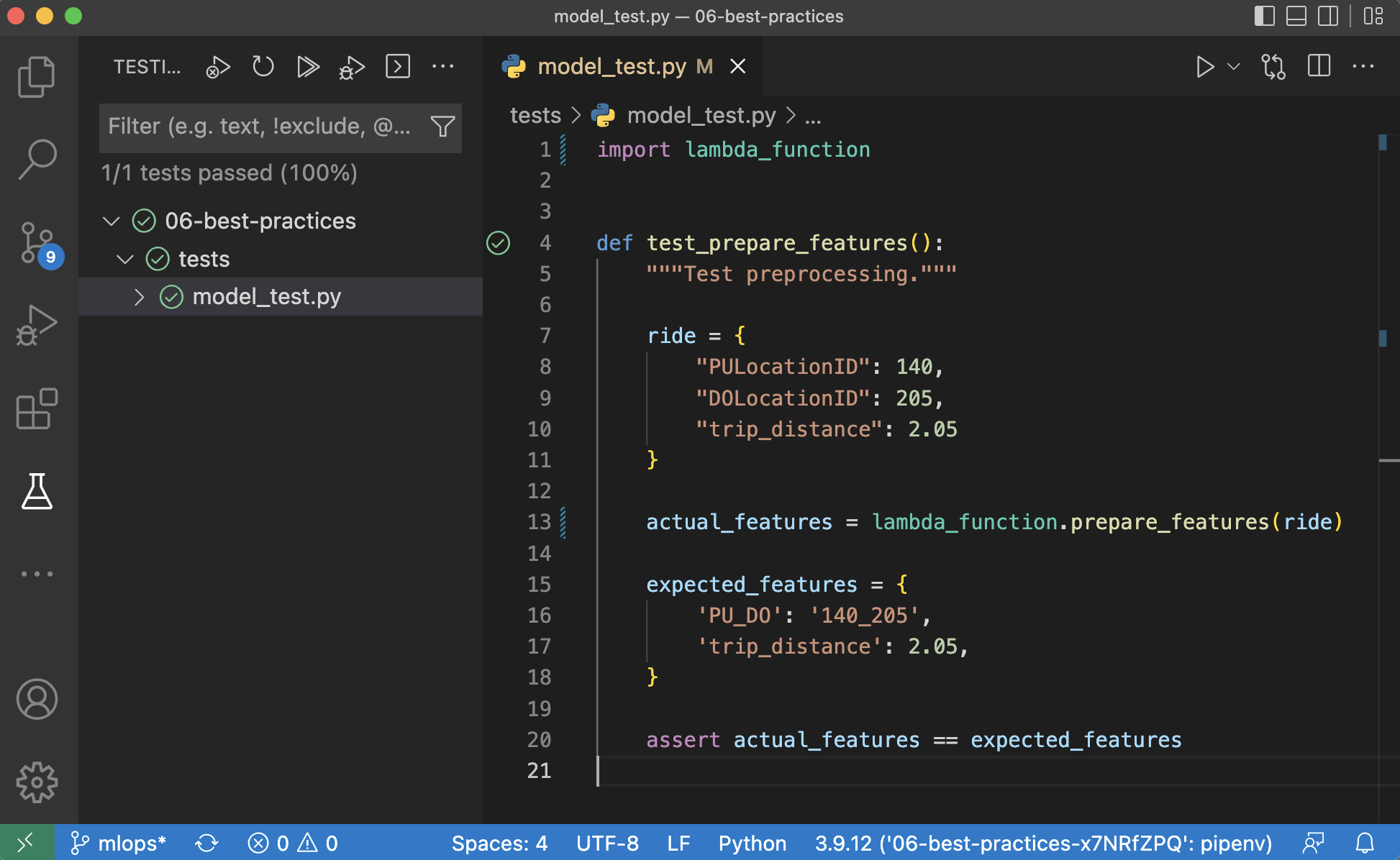
Fig. 124 Testing user interface in VS Code.#
Another thing we should always try is to deliberately break the tests. This makes sure that tests cover the changes being made. For example, we may forget adding assert statements which means the test are passed trivially.
Notice that unit tests act as invariants that must remain true even if particular implementation details around them changes. This is nice since the tests make sure that the important parts of the code are functioning even if we change or refactor things around it. And also allows fast iteration, we know that we are not making breaking changes to the code. In its extreme form, this practice is called test-driven development (TDD).
Refactoring the lambda function#
Note that we had to manually comment out things in our tests. This is not really great. Also, it would fail if our dev environment cannot connect to S3. A way to fix this is to create a special class which we can call Model containing all the logic of the original function, but with parts that are easier to test.
For this we modify lambda_function.py as follows:
# lambda_function.py
import model
import os
# Load environmental variables
PREDICTIONS_STREAM_NAME = os.getenv('PREDICTIONS_STREAM_NAME', 'ride_predictions')
RUN_ID = os.getenv('RUN_ID')
TEST_RUN = os.getenv('TEST_RUN', 'False') == 'True'
model_service = model.init(
predictions_stream_name=PREDICTIONS_STREAM_NAME,
run_id=RUN_ID,
test_run=TEST_RUN
)
def lambda_handler(event, context):
return model_service.lambda_handler(event)
Here predictions_stream_name is specified as the stream where the function writes to. The stream where the function reads from need not be specified since this is configured in AWS Lambda. Then, we need to specify run_id to determine the model in S3 to use. Finally, test_run is simply a flag to indicate that we are in development mode (i.e. so we don’t write on the output stream which may be already deployed during the development of this code). These are variables that are configured when the Docker container is run.
All of these variables determine a prediction service called model_service which abstracts away the process of predicting on an event. In particular, this means that we don’t test directly on the actual lambda_function that is exposed by the container. (Although, we will see later that this is still covered with integration tests, since these make sure that everything is working together.) This is implemented in the following class:
# model.py
import json
import boto3
import base64
import mlflow
def load_model(run_id: str):
logged_model = f's3://mlflow-models-ron/1/{run_id}/artifacts/model'
model = mlflow.pyfunc.load_model(logged_model)
return model
def base64_decode(encoded_data):
decoded_data = base64.b64decode(encoded_data).decode('utf-8')
ride_event = json.loads(decoded_data)
return ride_event
class ModelService:
def __init__(self, model, model_version):
self.model = model
self.model_version = model_version
def prepare_features(self, ride):
features = {}
features['PU_DO'] = '%s_%s' % (ride['PULocationID'], ride['DOLocationID'])
features['trip_distance'] = ride['trip_distance']
return features
def predict(self, features):
pred = self.model.predict(features)
return float(pred[0])
def lambda_handler(self, event):
predictions_events = []
for record in event['Records']:
encoded_data = record['kinesis']['data']
ride_event = base64_decode(encoded_data)
ride = ride_event['ride']
ride_id = ride_event['ride_id']
features = self.prepare_features(ride)
prediction = self.predict(features)
prediction_event = {
'model': 'ride_duration_prediction_model',
'version': self.model_version,
'prediction': {
'ride_duration': prediction,
'ride_id': ride_id
}
}
# if not TEST_RUN:
# kinesis_client = boto3.client('kinesis')
# kinesis_client.put_record(
# StreamName=PREDICTIONS_STREAM_NAME,
# Data=json.dumps(prediction_event),
# PartitionKey=str(ride_id)
# )
predictions_events.append(prediction_event)
return {
'predictions': predictions_events
}
def init(predictions_stream_name: str, run_id: str, test_run: bool):
model = load_model(run_id)
model_service = ModelService(model=model, model_version=run_id)
return model_service
Note that the attributes of the class are informed by the methods that we collect inside of it. For example, we also version the models with run_id, hence the model_version attribute. This information is packaged along with the prediction. Also notice that the functionality for writing outputs is commented out. For now, we focus on getting correct predictions.
Further unit tests#
Note that the unit tests should fail now after refactoring. Modifying the code so that it uses the ModelService class:
# tests/model_test.py
...
def test_prepare_features():
"""Test preprocessing."""
ride = {
"PULocationID": 130,
"DOLocationID": 205,
"trip_distance": 3.66
}
model_service = model.ModelService(model=None, model_version=None)
actual_features = model_service.prepare_features(ride)
expected_features = {
'PU_DO': '130_205',
'trip_distance': 3.66,
}
assert actual_features == expected_features
...
Adding more tests on units of functionalities. For example, we can test the decoding base 64 inputs.
# tests/model_test.py
...
def test_base64_decode():
base64_input = "eyAgICAgICAgICAicmlkZSI6IHsgICAgICAgICAgICAgICJQVUxvY2F0aW9uSUQiOiAxMzAsICAgICAgICAgICAgICAiRE9Mb2NhdGlvbklEIjogMjA1LCAgICAgICAgICAgICAgInRyaXBfZGlzdGFuY2UiOiAzLjY2ICAgICAgICAgIH0sICAgICAgICAgICJyaWRlX2lkIjogMTIzICAgICAgfQ=="
actual_result = model.base64_decode(base64_input)
expected_result = {
"ride": {
"PULocationID": 130,
"DOLocationID": 205,
"trip_distance": 3.66
},
"ride_id": 123
}
assert actual_result == expected_result
...
For now we are setting model=None since this functionality does not use any model. Now, we want to test predict so we want to have a model to test with. We want to avoid connecting to S3 in our dev environment as it adds additional overhead to our tests. Also, there is no reason yet to spend time on things like access credentials when we are only testing bits of functionality. So we will create a mock model which mimics all relevant attributes and methods of real models for prediction.
# tests/model_test.py
...
class ModelMock:
def __init__(self, value):
self.value = value
def predict(self, X):
n = len(X)
return [self.value] * n
def test_predict():
features = {
'PU_DO': '130_205',
'trip_distance': 3.66,
}
model_mock = ModelMock(value=10.0)
model_service = model.ModelService(model=model_mock, model_version=None)
actual_result = model_service.predict(features)
expected_result = 10.0
assert actual_result == expected_result
Finally, we would like to test the ModelService.lambda_handler function:
# tests/model_test.py
...
def test_lambda_handler():
event = {
"Records": [
{
"kinesis": {
"data": "eyAgICAgICAgICAicmlkZSI6IHsgICAgICAgICAgICAgICJQVUxvY2F0aW9uSUQiOiAxMzAsICAgICAgICAgICAgICAiRE9Mb2NhdGlvbklEIjogMjA1LCAgICAgICAgICAgICAgInRyaXBfZGlzdGFuY2UiOiAzLjY2ICAgICAgICAgIH0sICAgICAgICAgICJyaWRlX2lkIjogMTIzICAgICAgfQ==",
},
}
]
}
model_mock = ModelMock(value=10.0)
model_service = model.ModelService(model=model_mock, model_version="model-mock")
actual_result = model_service.lambda_handler(event)
expected_result = {
'predictions': [
{
'model': 'ride_duration_prediction_model',
'version': 'model-mock',
'prediction': {
'ride_duration': 10.0,
'ride_id': 123
}
}
]
}
assert actual_result == expected_result
Adding callbacks#
We covered pretty much everything except the writing on the output stream. Note that this part of the lambda_handler code seems out of place. All other functionalities are geared towards prediction and now, if we include writing on an output stream, the model service has to know about the Kinesis client, the stream name, etc.
Instead, what we can do is define a separate unit that handles what happens after the prediction is done, i.e. a callback on prediction events. This is called every time the model service completes a prediction. Putting something on the Kinesis stream would be one of the callbacks.
# model.py
...
class ModelService:
def __init__(self, model, model_version, callbacks=None):
self.model = model
self.model_version = model_version
self.callbacks = callbacks or []
...
def lambda_handler(self, event):
predictions_events = []
for record in event['Records']:
...
prediction_event = {
'model': 'ride_duration_prediction_model',
'version': self.model_version,
'prediction': {
'ride_duration': prediction,
'ride_id': ride_id
}
}
for callback in self.callbacks: # !
callback(prediction_event)
predictions_events.append(prediction_event)
return {
'predictions': predictions_events
}
...
Notice that callbacks act on prediction events, e.g. writes them to Kinesis streams. Below we modify the init function to include the Kinesis callback which we package into a class since we need a callable. Here we simply pass a reference to the put_record method which acts on prediction events in the callbacks list.
# model.py
...
class KinesisCallback:
def __init__(self, kinesis_client, predictions_stream_name):
self.kinesis_client = kinesis_client
self.predictions_stream_name = predictions_stream_name
def put_record(self, prediction_event):
ride_id = prediction_event['prediction']['ride_id']
self.kinesis_client.put_record(
StreamName=self.predictions_stream_name,
Data=json.dumps(prediction_event),
PartitionKey=str(ride_id)
)
def init(predictions_stream_name: str, run_id: str, test_run: bool):
"""Initialize model_service for lambda_function module."""
model = load_model(run_id)
callbacks = []
if not test_run:
kinesis_client = boto3.client('kinesis')
kinesis_callback = KinesisCallback(kinesis_client, predictions_stream_name)
callbacks.append(kinesis_callback.put_record)
model_service = ModelService(model=model, model_version=run_id, callbacks=callbacks)
return model_service
This looks really really nice. We will test this later with a local cloud setup!
Appendix: Source code#
See here for the finished code for this section. Final directory structure at the end should look like:
.
├── Dockerfile
├── Pipfile
├── Pipfile.lock
├── lambda_function.py
├── model.py
└── tests
├── __init__.py
└── model_test.py
Integration tests#
In the last section, we refactored our original code for our lambda function and created tests. But these tests are quite limited. They only test only functions. They don’t test that the entire thing still works. Recall that we have test_docker.py which sort of checks that predictions still work for the container as a whole. At this point, we can build and run the container to make sure that this code still works as a whole.
Remarks. Note that the goal of integration testing is not to test the accuracy of predictions, but only that prediction with the Lambda container works and it has the correct input and output signature.
Testing the Lambda container#
Bulding and running the container and running the test_docker script can be done along with writing the unit tests, or after refactoring, so that no drastic change is done without making sure everything still are integrated well. But we only get to do this here for the sake of presentation.
FROM public.ecr.aws/lambda/python:3.9
RUN pip install -U pip
RUN pip install pipenv
COPY [ "Pipfile", "Pipfile.lock", "./" ]
RUN pipenv install --system --deploy
COPY [ "lambda_function.py", "model.py", "./" ]
CMD [ "lambda_function.lambda_handler" ]
Building:
docker build -t stream-model-duration:v2 .
[+] Building 1.2s (11/11) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 37B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for public.ecr.aws/lambda/python: 1.0s
=> [1/6] FROM public.ecr.aws/lambda/python:3.9@sha256:3dda276 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 2.64kB 0.0s
=> CACHED [2/6] RUN pip install -U pip 0.0s
=> CACHED [3/6] RUN pip install pipenv 0.0s
=> CACHED [4/6] COPY [ Pipfile, Pipfile.lock, ./ ] 0.0s
=> CACHED [5/6] RUN pipenv install --system --deploy 0.0s
=> [6/6] COPY [ lambda_function.py, model.py, ./ ] 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:26e91ec8b6a57ba80437dc8ee278c92dfd 0.0s
=> => naming to docker.io/library/stream-model-duration:v2 0.0s
Running:
docker run -it --rm -p 8080:8080 --env-file .env stream-model-duration:v2
24 Jul 2022 02:31:10,656 [INFO] (rapid) exec '/var/runtime/bootstrap' (cwd=/var/task, handler=)
24 Jul 2022 02:31:14,705 [INFO] (rapid) extensionsDisabledByLayer(/opt/disable-extensions-jwigqn8j) -> stat /opt/disable-extensions-jwigqn8j: no such file or directory
24 Jul 2022 02:31:14,707 [WARNING] (rapid) Cannot list external agents error=open /opt/extensions: no such file or directory
START RequestId: aa21ad77-9ae1-49bc-a7d2-a7bfa3e42266 Version: $LATEST
Note that this uses a .env file for defining environmental variables:
# .env
RUN_ID=f4e2242a53a3410d89c061d1958ae70a
TEST_RUN=True
PREDICTIONS_STREAM_NAME=ride_predictions
AWS_PROFILE=mlops
AWS_DEFAULT_REGION=us-east-1
Testing prediction using the following script:
# test_docker.py
import requests
event = {
"Records": [
{
"kinesis": {
"kinesisSchemaVersion": "1.0",
"partitionKey": "1",
"sequenceNumber": "49630706038424016596026506533782471779140474214180454402",
"data": "eyAgICAgICAgICAicmlkZSI6IHsgICAgICAgICAgICAgICJQVUxvY2F0aW9uSUQiOiAxMzAsICAgICAgICAgICAgICAiRE9Mb2NhdGlvbklEIjogMjA1LCAgICAgICAgICAgICAgInRyaXBfZGlzdGFuY2UiOiAzLjY2ICAgICAgICAgIH0sICAgICAgICAgICJyaWRlX2lkIjogMTIzICAgICAgfQ==",
"approximateArrivalTimestamp": 1655944485.718
},
"eventSource": "aws:kinesis",
"eventVersion": "1.0",
"eventID": "shardId-000000000000:49630706038424016596026506533782471779140474214180454402",
"eventName": "aws:kinesis:record",
"invokeIdentityArn": "arn:aws:iam::241297376613:role/lambda-kinesis-role",
"awsRegion": "us-east-1",
"eventSourceARN": "arn:aws:kinesis:us-east-1:241297376613:stream/ride_events"
}
]
}
if __name__ == "__main__":
url = 'http://localhost:8080/2015-03-31/functions/function/invocations'
response = requests.post(url, json=event)
print(response.json())
Running python test_docker.py on the terminal. Looks like the lambda function is still working inside the container. That is, it can do download the model from S3, decode the input data, and make a prediction that is exposed in the lambda container.
$ pipenv run python test_docker.py
{
'predictions': [
{
'model': 'ride_duration_prediction_model',
'version': 'f4e2242a53a3410d89c061d1958ae70a',
'prediction': {
'ride_duration': 18.210770674183355,
'ride_id': 123
}
}
]
}
Note that this isn’t yet a proper test, i.e. we just printed something and checked the print if it looked correct. In the next section, we change this into something that can be automated with pytest.
Differences with DeepDiff#
To get fine-grained control over the differences between JSON outputs, we install a dev dependency called DeepDiff. This library works for any two Python objects, so this can be a really useful tool to use with the pytest library.
pipenv install --dev deepdiff
Modifying our test_docker.py script to simulate change, also adding an assert to trigger an exception:
# test_docker.py
...
url = 'http://localhost:8080/2015-03-31/functions/function/invocations'
actual_response = requests.post(url, json=event).json()
print('actual response:')
print(json.dumps(actual_response, indent=4))
expected_response = {
'predictions': [
{
'model': 'ride_duration_prediction_model',
'version': 'f4e2242a53a3410d89c061d1958ae70a',
'prediction': {
'ride_duration': 18.0, # <-
'ride_id': 123
}
}
]
}
diff = DeepDiff(actual_response, expected_response)
print('\ndiff:')
print(json.dumps(diff, indent=4))
assert len(diff) == 0
Running this we get:
$ python test_docker.py
actual response:
{
"predictions": [
{
"model": "ride_duration_prediction_model",
"version": "f4e2242a53a3410d89c061d1958ae70a",
"prediction": {
"ride_duration": 18.210770674183355,
"ride_id": 123
}
}
]
}
diff:
{
"values_changed": {
"root['predictions'][0]['prediction']['ride_duration']": {
"new_value": 18.210770674183355,
"old_value": 18.0
}
}
}
Traceback (most recent call last):
File "/Users/particle1331/code/ok-transformer/docs/nb/mlops/06-best-practices/code/integration-test/test_docker.py", line 52, in <module>
assert len(diff) == 1
AssertionError
Here it is indicated precisely where in the passed object did the values change, i.e. from 18.0 to 18.210[...] in root['predictions'][0]['prediction']['ride_duration']. For numeric values, e.g. predictions, we can pass math_epsilon=0.1 in DeepDiff which compares numbers with lambda x, y: math.isclose(x, y, abs_tol=0.1). See docs for more options.
Adding a local model for testing#
Since we only want to test whether our container is able to make predictions, we want to have the option of using a local model. Note that everything should still work since we write the code in such a way that everything is the same except for the particular model path. Also, the accuracy of the model is not an issue since that is tested elsewhere (e.g. before staging).
First, we copy the contents of an MLflow artifacts folder into integration-test/model/ as shown:
Note that these are artifacts of a different MLflow run than what we have been loading from S3. Refactoring the code a bit to use model_location and model_version which are now more general. All environmental variables are loaded in the lambda_function script which is sort of our main file:
# lambda_function.py
PREDICTIONS_STREAM_NAME = os.getenv('PREDICTIONS_STREAM_NAME', 'ride_predictions')
MODEL_LOCATION = os.getenv('MODEL_LOCATION')
MODEL_BUCKET = os.getenv('MODEL_BUCKET', 'mlflow-models-ron')
EXPERIMENT_ID = os.getenv('MLFLOW_EXPERIMENT_ID', '1')
RUN_ID = os.getenv('RUN_ID')
TEST_RUN = os.getenv('TEST_RUN', 'False') == 'True'
if MODEL_LOCATION is None:
logged_model = f's3://{MODEL_BUCKET}/{EXPERIMENT_ID}/{RUN_ID}/artifacts/model'
model_version = RUN_ID
else:
model_location = MODEL_LOCATION
model_version = 'localtest'
model_service = model.init(
predictions_stream_name=PREDICTIONS_STREAM_NAME,
model_location=model_location,
model_version=model_version,
test_run=TEST_RUN,
)
def lambda_handler(event, context):
return model_service.lambda_handler(event)
We introduce the model_location variable which is either an S3 path or a local path. Model version depends on whether the model comes from local disk or from S3. All functions are modified accordingly, such as model.init which we look at below. Note that load_model now just abstracts the load script from MLflow, instead of constructing the path.
# model.py
...
def load_model(model_location):
"""Load MLflow model from path."""
model = mlflow.pyfunc.load_model(model_location)
return model
...
def init(
predictions_stream_name: str,
model_location: str, # <-
model_version: str, # <-
test_run: bool
):
"""Initialize model_service for lambda_function module."""
model = load_model(model_location) # <-
...
model_service = ModelService(
model=model,
model_version=model_version, # <-
callbacks=callbacks,
)
return model_service
Note that the Dockerfile will not change, but we will mount the local model folder to the container while it is running. The following script will be executed inside the integation-test folder.
docker build -t stream-model-duration:v2 .
docker run -it --rm \
-p 8080:8080 \
--env-file .env \
-v $(pwd)/model:/app/model \
stream-model-duration:v2
Keep in mind that model location is relative to the container, not the dev environment:
# integration-test/.env
MODEL_LOCATION=/app/model
RUN_ID=f4e2242a53a3410d89c061d1958ae70a
EXPERIMENT_ID=1
TEST_RUN=True
AWS_PROFILE=mlops
AWS_DEFAULT_REGION=us-east-1
This is a different model so we have to modify the expected response with the new prediction:
import joblib
model_path = 'code/integration-test/model/model.pkl'
model = joblib.load(model_path)
expected_features = {
'PU_DO': '130_205',
'trip_distance': 3.66,
}
print(f'{model.predict(expected_features)[0]:.10f}')
18.2536313889
Modifying accordingly:
# integration_test/test_docker.py
...
expected_response = {
'predictions': [
{
'model': 'ride_duration_prediction_model',
'version': 'localtest', # <-
'prediction': {
'ride_duration': 18.2536313889, # <-
'ride_id': 123
}
}
]
}
diff = DeepDiff(expected_response, actual_response, math_epsilon=1e-7) # <-
print('\ndiff:')
print(json.dumps(diff, indent=4))
...
Running the container test:
!python code/integration-test/test_docker.py
actual response:
{
"predictions": [
{
"model": "ride_duration_prediction_model",
"version": "localtest",
"prediction": {
"ride_duration": 18.25363138888259,
"ride_id": 123
}
}
]
}
diff:
{}
Checking if unit tests are still working:
!pytest code/tests .
============================= test session starts ==============================
platform darwin -- Python 3.9.12, pytest-7.1.2, pluggy-1.0.0
rootdir: /Users/particle1331/code/ok-transformer/docs/nb/mlops/06-best-practices
plugins: anyio-3.5.0
collected 4 items
code/tests/model_test.py .... [100%]
============================== 4 passed in 1.50s ===============================
Automating the test#
Observe that we have to build the Docker image, run it, and run the test script. In this section, we will automate this process completely with a simple script. But we want to change the run script to docker-compose because it would be easier to track all these configuration in a .yml file:
# integration-test/docker-compose.yml
services:
backend:
image: ${LOCAL_IMAGE_NAME}
ports:
- "8080:8080"
environment:
- PREDICTIONS_STREAM_NAME=ride_predictions
- TEST_RUN=True
- AWS_DEFAULT_REGION=us-east-1
- MODEL_LOCATION=/app/model
volumes:
- "./model:/app/model"
Continuing now with our script integration-test/run.sh:
#!/usr/bin/env bash
cd "$(dirname "$0")"
export LOCAL_TAG=`date +"%Y-%m-%d-%H-%M"`
export LOCAL_IMAGE_NAME="stream-model-duration:${LOCAL_TAG}"
docker build -t ${LOCAL_IMAGE_NAME} ..
docker-compose up -d
sleep 1
pipenv run python test_docker.py
docker-compose down
The first line ensures that this runs in bash. Then, it will change directory to the same directory as test_docker.py. It will go one level up to build the Docker image. Next, the script executes docker-compose up -d. This runs the Docker image with ${LOCAL_IMAGE_NAME} in detached mode. Otherwise, it will just keep running in the terminal and the next commands will not push through. It’s a good idea to give the terminal some time after starting the Docker container, so we execute sleep 1. Then, we run our container test script. Finally, we remove the resources with docker-compose down.
Running the script:
$ sh run.sh
[+] Building 0.4s (11/11) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 37B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for public.ecr.aws/lambda/python: 0.3s
=> [internal] load build context 0.0s
=> => transferring context: 128B 0.0s
=> [1/6] FROM public.ecr.aws/lambda/python:3.9@sha256:3dda276 0.0s
=> CACHED [2/6] RUN pip install -U pip 0.0s
=> CACHED [3/6] RUN pip install pipenv 0.0s
=> CACHED [4/6] COPY [ Pipfile, Pipfile.lock, ./ ] 0.0s
=> CACHED [5/6] RUN pipenv install --system --deploy 0.0s
=> CACHED [6/6] COPY [ lambda_function.py, model.py, ./ ] 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:ce4bdf23e33a8cd20e3d0906ac71f92470 0.0s
=> => naming to docker.io/library/stream-model-duration:2022- 0.0s
[+] Running 2/2
⠿ Network integration-test_default Created 0.0s
⠿ Container integration-test-backend-1 Started 0.4s
Loading .env environment variables...
actual response:
{
"predictions": [
{
"model": "ride_duration_prediction_model",
"version": "localtest",
"prediction": {
"ride_duration": 18.253631388882592,
"ride_id": 123
}
}
]
}
diff:
{}
[+] Running 2/1
⠿ Container integration-test-backend-1 Removed 0.4s
⠿ Network integration-test_default Removed 0.0s
Notice that we also change the container tag to the current date and time:
!docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
stream-model-duration 2022-07-25-20-03 ce4bdf23e33a 3 hours ago 1.34GB
Returning error codes#
Error codes of previous executed commands can obtained in bash using $?. This can be used in CI/CD pipelines. But here we will use it to indicate that our integration test failed. The error code of the integration test can be stored as follows:
...
pipenv run python test_docker.py
ERROR_CODE=$?
if [ ${ERROR_CODE} != 0 ]; then
docker-compose logs
fi
docker-compose down
exit ${ERROR_CODE}
The last line returns the error code to the terminal. Testing this with the current tests will return error code 0. Failing the test will result in an error code of 1. This can be used in a CI/CD job resulting in a failed job and we can return the logs.
Code quality#
In this section, we will talk about code quality. Specifically, we talk about linting and code formatting. Previously, we already covered code quality, but in the point of view of reliability. That code is doing what it is supposed to do. Now we want to talk about the readability as well as code quality. This is also related to maintainability of the code base.
For static code analysis, i.e. detecting code smells, we will use pylint. And for code formatting, or styling, we will be using Black. Both of these tools adhere to PEP 8, the Python style guide. Finally, we will use isort for ordering our imports.
Linting#
First, let’s run pylint for all files in the code/ directory to see what it outputs:
$ pylint --recursive=y .
************* Module model
model.py:12:53: C0303: Trailing whitespace (trailing-whitespace)
model.py:50:0: C0303: Trailing whitespace (trailing-whitespace)
model.py:53:0: C0303: Trailing whitespace (trailing-whitespace)
...
model.py:1:0: C0114: Missing module docstring (missing-module-docstring)
model.py:16:0: C0116: Missing function or method docstring (missing-function-docstring)
model.py:22:0: C0115: Missing class docstring (missing-class-docstring)
model.py:29:4: C0116: Missing function or method docstring (missing-function-docstring)
model.py:31:28: C0209: Formatting a regular string which could be a f-string (consider-using-f-string)
...
model.py:74:0: C0115: Missing class docstring (missing-class-docstring)
model.py:80:4: C0116: Missing function or method docstring (missing-function-docstring)
model.py:74:0: R0903: Too few public methods (1/2) (too-few-public-methods)
model.py:4:0: C0411: standard import "import base64" should be placed before "import boto3" (wrong-import-order)
model.py:1:0: W0611: Unused import os (unused-import)
model.py:6:0: W0611: Unused import joblib (unused-import)
************* Module lambda_function
lambda_function.py:1:0: C0114: Missing module docstring (missing-module-docstring)
lambda_function.py:18:4: C0103: Constant name "model_version" doesn't conform to UPPER_CASE naming style (invalid-name)
lambda_function.py:29:0: C0116: Missing function or method docstring (missing-function-docstring)
lambda_function.py:29:26: W0613: Unused argument 'context' (unused-argument)
lambda_function.py:2:0: C0411: standard import "import os" should be placed before "import model" (wrong-import-order)
************* Module tests.model_test
tests/model_test.py:6:26: C0303: Trailing whitespace (trailing-whitespace)
tests/model_test.py:24:0: C0303: Trailing whitespace (trailing-whitespace)
tests/model_test.py:35:0: C0301: Line too long (245/100) (line-too-long)
tests/model_test.py:36:0: C0303: Trailing whitespace (trailing-whitespace)
...
tests/model_test.py:8:22: C0103: Argument name "X" doesn't conform to snake_case naming style (invalid-name)
tests/model_test.py:9:8: C0103: Variable name "n" doesn't conform to snake_case naming style (invalid-name)
tests/model_test.py:4:0: R0903: Too few public methods (1/2) (too-few-public-methods)
tests/model_test.py:33:0: C0116: Missing function or method docstring (missing-function-docstring)
...
************* Module test_docker
integration-test/test_docker.py:14:0: C0301: Line too long (251/100) (line-too-long)
integration-test/test_docker.py:19:0: C0301: Line too long (103/100) (line-too-long)
integration-test/test_docker.py:38:54: C0303: Trailing whitespace (trailing-whitespace)
integration-test/test_docker.py:1:0: C0114: Missing module docstring (missing-module-docstring)
integration-test/test_docker.py:29:0: C0103: Constant name "url" doesn't conform to UPPER_CASE naming style (invalid-name)
-----------------------------------
Your code has been rated at 5.56/10
So we see that it has a bunch of rules, for example, no trailing whitespaces. These are whitespaces at the end of each line. Missing docstrings are also flagged. Another recommendation is to use f-strings instead of .format for string formatting.
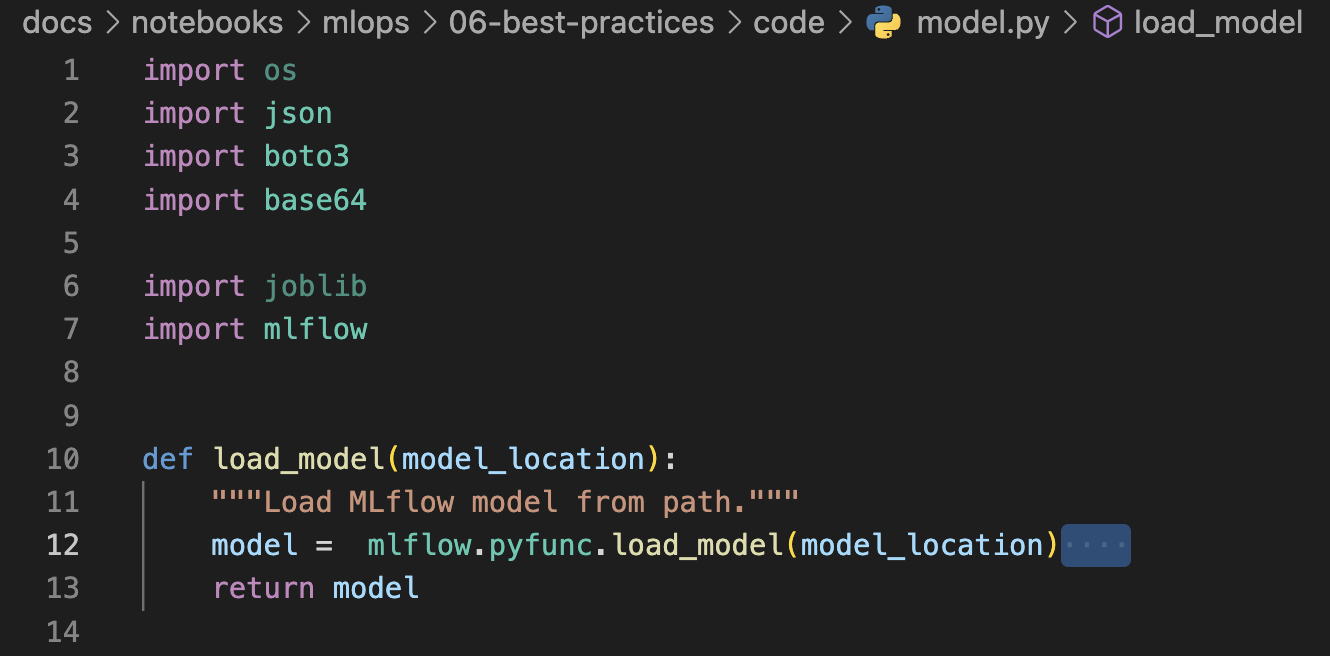
Fig. 125 Pylint flags trailing whitespace at line 12, after column 53, of model.py.#
Something more convenient in VS Code is to CMD+SHIFT+P and Python: Select Linter to get warnings on the UI level. This is easier than reading through the above output.
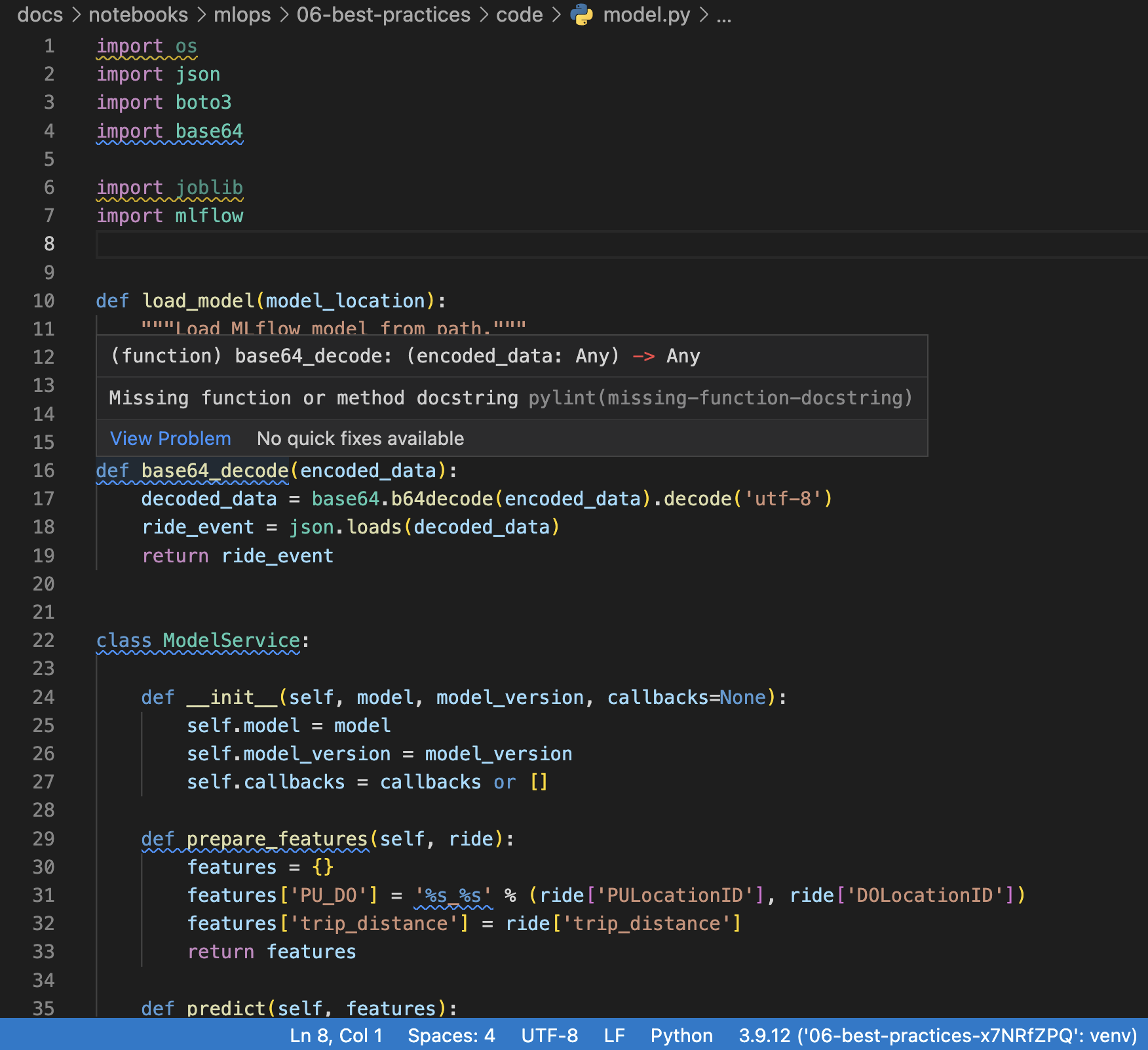
Fig. 126 Highlighted warnings in VS Code along with an explanation from pylint.#
Some of these errors we don’t really care about. So we can actually configure pylint using pyproject.toml. See here for all pylint messages. Messages that we don’t care about can also be copied from the above output (e.g. too-few-public-methods or invalid-name for variables X and n which are fine for machine learning applications).
# pyproject.toml
[tool.pylint.messages_control]
max-line-length = 88
disable = [
"missing-docstring",
"unused-argument",
"missing-class-docstring",
"missing-function-docstring",
"invalid-name",
]
Running pylint again. Note that score improves:
❯ pylint --recursive=y .
************* Module /Users/particle1331/code/ok-transformer/docs/nb/mlops/06-best-practices/code/pyproject.toml
pyproject.toml:1:0: W0012: Unknown option value for '--disable', expected a valid pylint message and got 'final-newline' (unknown-option-value)
************* Module model
model.py:12:53: C0303: Trailing whitespace (trailing-whitespace)
...
model.py:31:28: C0209: Formatting a regular string which could be a f-string (consider-using-f-string)
model.py:4:0: C0411: standard import "import base64" should be placed before "import boto3" (wrong-import-order)
model.py:1:0: W0611: Unused import os (unused-import)
model.py:6:0: W0611: Unused import joblib (unused-import)
************* Module lambda_function
lambda_function.py:18:4: C0103: Constant name "model_version" doesn't conform to UPPER_CASE naming style (invalid-name)
lambda_function.py:2:0: C0411: standard import "import os" should be placed before "import model" (wrong-import-order)
************* Module tests.model_test
tests/model_test.py:6:26: C0303: Trailing whitespace (trailing-whitespace)
tests/model_test.py:24:0: C0303: Trailing whitespace (trailing-whitespace)
tests/model_test.py:35:0: C0301: Line too long (245/88) (line-too-long)
...
tests/model_test.py:8:22: C0103: Argument name "X" doesn't conform to snake_case naming style (invalid-name)
tests/model_test.py:9:8: C0103: Variable name "n" doesn't conform to snake_case naming style (invalid-name)
************* Module test_docker
integration-test/test_docker.py:13:0: C0301: Line too long (93/88) (line-too-long)
...
integration-test/test_docker.py:38:54: C0303: Trailing whitespace (trailing-whitespace)
integration-test/test_docker.py:29:0: C0103: Constant name "url" doesn't conform to UPPER_CASE naming style (invalid-name)
------------------------------------------------------------------
Your code has been rated at 7.01/10 (previous run: 5.64/10, +1.37)
If we want to suppress messages for specific parts of the code, we can use the following:
# model.py
...
class KinesisCallback:
# pylint: disable=too-few-public-methods
def __init__(self, kinesis_client, predictions_stream_name):
self.kinesis_client = kinesis_client
self.predictions_stream_name = predictions_stream_name
...
For line-too-long for base 64 inputs, we define the following function which is used to read data.b64 which stores the encoded string. Note that pylint catches error of failing to specify the encoding. This is actually useful since not specifying the encoding can fail in Linux systems.
# model.py
...
def read_text(file):
test_directory = pathlib.Path(__file__).parent
with open(test_directory / file, 'rt', encoding='utf-8') as f_in:
return f_in.read().strip()
...
Similarly, for integration-test/test_docker.py, we save and load the event from an event.json file. After all of these changes, and removing unused imports, running pylint --recursive=y . gives a score of 8.10/10. The messages that are left are all regarding whitespaces and import ordering. For these, we will use an tools for automatic code formatting and import sorter.
Formatting#
To view changes that are not yet applied we can use the following command:
❯ black --diff model.py
--- model.py 2022-07-29 20:16:30.129099 +0000
+++ model.py 2022-07-29 20:26:13.503436 +0000
@@ -5,106 +5,101 @@
import mlflow
def load_model(model_location):
"""Load MLflow model from path."""
- model = mlflow.pyfunc.load_model(model_location)
+ model = mlflow.pyfunc.load_model(model_location)
return model
def base64_decode(encoded_data):
- decoded_data = base64.b64decode(encoded_data).decode('utf-8')
+ decoded_data = base64.b64decode(encoded_data).decode("utf-8")
ride_event = json.loads(decoded_data)
return ride_event
class ModelService:
-
def __init__(self, model, model_version, callbacks=None):
self.model = model
self.model_version = model_version
self.callbacks = callbacks or []
def prepare_features(self, ride):
features = {}
- features['PU_DO'] = f"{ride['PULocationID']}_{ride['DOLocationID']}"
- features['trip_distance'] = ride['trip_distance']
+ features["PU_DO"] = f"{ride['PULocationID']}_{ride['DOLocationID']}"
+ features["trip_distance"] = ride["trip_distance"]
return features
def predict(self, features):
pred = self.model.predict(features)
return float(pred[0])
-
def lambda_handler(self, event):
predictions_events = []
- for record in event['Records']:
- encoded_data = record['kinesis']['data']
+ for record in event["Records"]:
+ encoded_data = record["kinesis"]["data"]
ride_event = base64_decode(encoded_data)
- ride = ride_event['ride']
- ride_id = ride_event['ride_id']
-
+ ride = ride_event["ride"]
+ ride_id = ride_event["ride_id"]
+
features = self.prepare_features(ride)
prediction = self.predict(features)
-
+
prediction_event = {
- 'model': 'ride_duration_prediction_model',
- 'version': self.model_version,
- 'prediction': {
- 'ride_duration': prediction,
- 'ride_id': ride_id,
- }
+ "model": "ride_duration_prediction_model",
+ "version": self.model_version,
+ "prediction": {
+ "ride_duration": prediction,
+ "ride_id": ride_id,
+ },
}
for callback in self.callbacks:
callback(prediction_event)
-
+
predictions_events.append(prediction_event)
-
- return {
- 'predictions': predictions_events
- }
+ return {"predictions": predictions_events}
class KinesisCallback:
# pylint: disable=too-few-public-methods
def __init__(self, kinesis_client, predictions_stream_name):
self.kinesis_client = kinesis_client
self.predictions_stream_name = predictions_stream_name
def put_record(self, prediction_event):
- ride_id = prediction_event['prediction']['ride_id']
+ ride_id = prediction_event["prediction"]["ride_id"]
self.kinesis_client.put_record(
StreamName=self.predictions_stream_name,
Data=json.dumps(prediction_event),
- PartitionKey=str(ride_id)
+ PartitionKey=str(ride_id),
)
def init(
- predictions_stream_name: str,
- model_location: str,
- model_version: str,
- test_run: bool
- ):
+ predictions_stream_name: str,
+ model_location: str,
+ model_version: str,
+ test_run: bool,
+):
"""Initialize model_service for lambda_function module."""
model = load_model(model_location)
-
+
callbacks = []
if not test_run:
- kinesis_client = boto3.client('kinesis')
+ kinesis_client = boto3.client("kinesis")
kinesis_callback = KinesisCallback(kinesis_client, predictions_stream_name)
callbacks.append(kinesis_callback.put_record)
model_service = ModelService(
- model=model,
- model_version=model_version,
+ model=model,
+ model_version=model_version,
callbacks=callbacks,
)
-
+
return model_service
would reformat model.py
All done! ✨ 🍰 ✨
1 file would be reformatted.
Note that this mostly involve replacing single quotes with double quotes, adding trailing commas to last items, and removing whitespaces. This looks fine so let’s apply it:
$ black model.py
reformatted model.py
All done! ✨ 🍰 ✨
1 file reformatted.
$ git status
On branch mlops
Your branch is up to date with 'origin/mlops'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: model.py
no changes added to commit (use "git add" and/or "git commit -a")
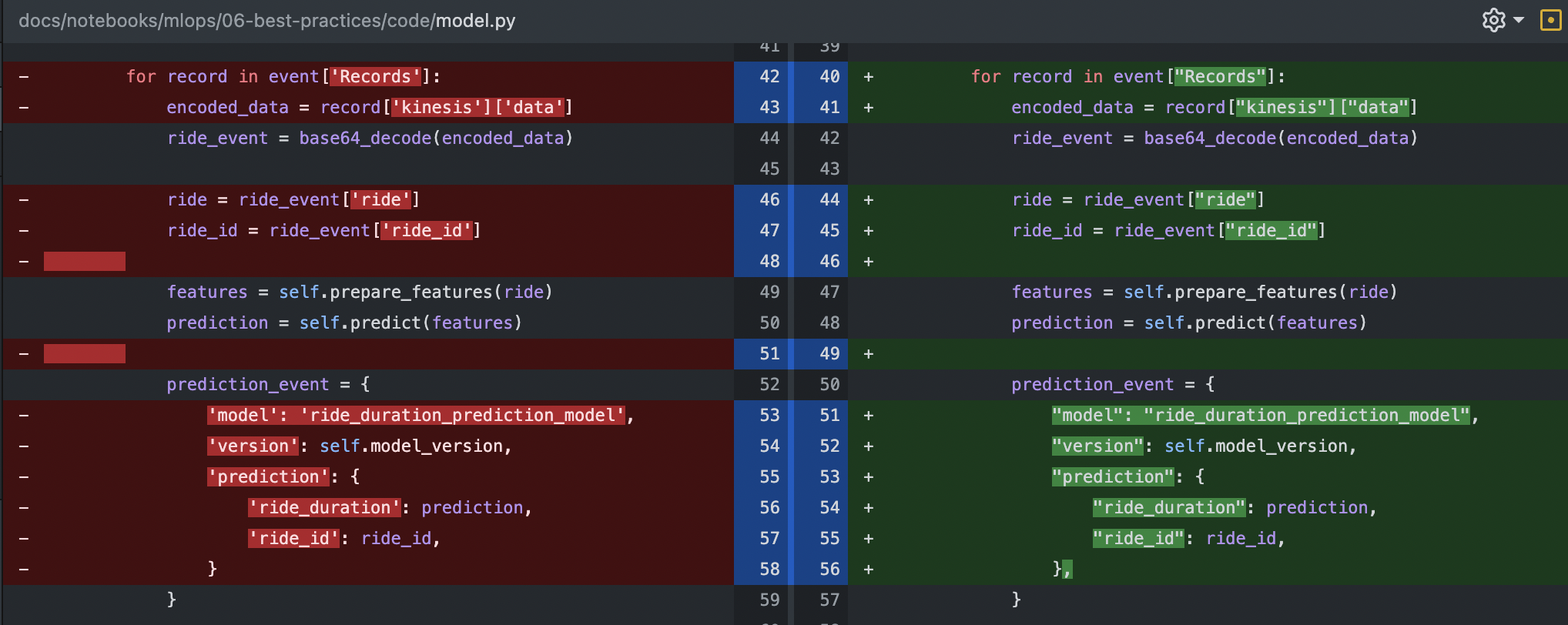
Fig. 127 Changes in model.py after using black.#
For black to not single quotes we can use the flag -S or --skip-string-normalization. Note that if we want black to not convert manually multi-line formatted dictionaries to one-liners we can add a trailing comma on the last item. Or we can add this in the pyproject.toml for black:
# pyproject.toml
...
[tool.black]
line-length = 88
target-version = ['py39']
skip-string-normalization = true
Imports#
Running pylint again shows that we only have import ordering left:
$ pylint --recursive=y .
************* Module model
model.py:3:0: C0411: standard import "import base64" should be placed before "import boto3" (wrong-import-order)
************* Module lambda_function
lambda_function.py:2:0: C0411: standard import "import os" should be placed before "import model" (wrong-import-order)
************* Module tests.model_test
tests/model_test.py:2:0: C0411: standard import "import pathlib" should be placed before "import model" (wrong-import-order)
------------------------------------------------------------------
Your code has been rated at 9.75/10 (previous run: 9.75/10, +0.00)
For this we will use isort. The following configuration sorts imports in increasing length, for readability. Here multi_line_output = 3 is the familiar convention where break imports into multiple lines by means of parentheses (see here).
# pyproject.toml
...
[tool.isort]
multi_line_output = 3
length_sort = true
Running isort and pylint now:
$ isort .
Fixing code/model.py
Fixing code/lambda_function.py
Fixing code/tests/model_test.py
Fixing code/integration-test/test_docker.py
$ pylint --recursive=y .
-------------------------------------------------------------------
Your code has been rated at 10.00/10 (previous run: 9.75/10, +0.25)
Git pre-commit hooks#
The nice thing about the tools discussed in the previous section is that these can all be run automatically. For example, in the following order. In this section, we will see how to do this using pre-commit hooks.
isort .
black .
pylint --recursive=y .
pytest tests/
sh integration-test/run.sh