Optimization#



Readings: [CS182-lec4] [UvA-Tutorial4]
Introduction#
Recall that we can visualize \(\mathcal{L}_{\mathcal{D}}(\boldsymbol{\Theta})\) as a surface (Fig. 17). This is also known as the loss landscape. Gradient descent finds the minimum by locally moving in the direction of greatest decrease in loss (Fig. 18). The step size depends on the learning rate that has to be tuned well: a too large value can result in overshooting the minimum, while a too small learning rate can result in slow convergence or being stuck in a local minimum. In this notebook, we will discuss situations where gradient descent works, situations where it works poorly, and ways we can improve it.
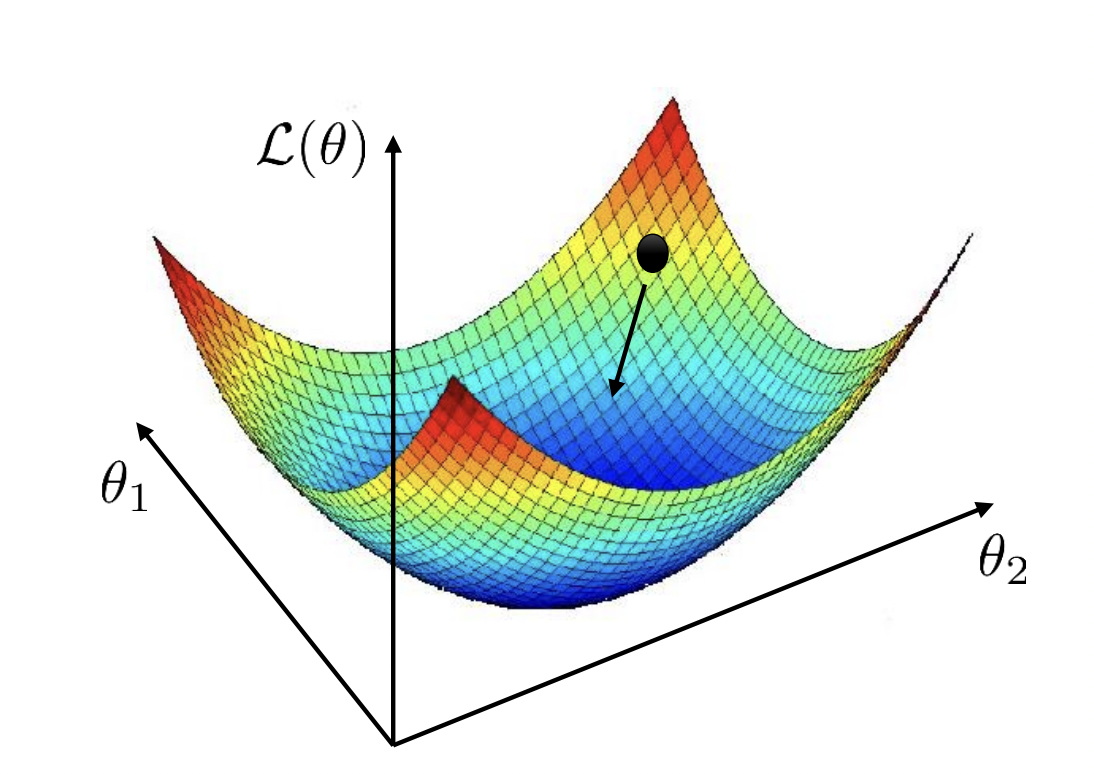
Fig. 17 Loss surface for a model with two weights. Source: [CS182-lec4]#
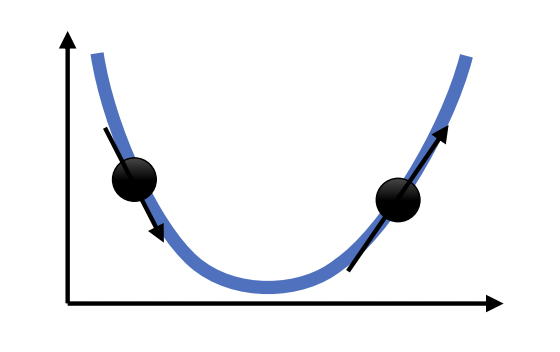
Fig. 18 Gradient descent in 1-dimension. Next step moves opposite to the direction of the slope. Moreover, step size is scaled based on the magnitude of the slope. Source: [CS182-lec4]#
Gradient descent#
To experiment with GD algorithms, we create a template class. The template implements a method for zeroing out the gradients.
The only method that needs to be changed is how to update parameters in update_param for specific algorithms.
import torch
import torch.nn as nn
class OptimizerBase:
def __init__(self, params: list, lr: float):
self.params = params
self.lr = lr
def zero_grad(self):
for p in self.params:
if p.grad is None:
continue
p.grad.detach_()
p.grad.zero_()
@torch.no_grad()
def step(self):
for p in self.params:
if p.grad is None:
continue
self.update_param(p)
def update_param(self, p):
raise NotImplementedError
Our first algorithm is GD which we discussed in the previous notebook:
class GD(OptimizerBase):
def __init__(self, params, lr):
super().__init__(params, lr)
def update_param(self, p):
p += -self.lr * p.grad
We will test with the following synthetic loss surface (i.e. not generated with data):
# https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial4/Optimization_and_Initialization.html
def pathological_loss(w0, w1):
l1 = torch.tanh(w0) ** 2 + 0.01 * torch.abs(w1)
l2 = torch.sigmoid(w1)
return l1 + l2
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from matplotlib_inline import backend_inline
from mpl_toolkits.mplot3d import Axes3D
backend_inline.set_matplotlib_formats('svg')
def plot_surface(ax, f, title="", x_min=-5, x_max=5, y_min=-5, y_max=5, N=50):
x = np.linspace(x_min, x_max, N)
y = np.linspace(y_min, y_max, N)
X, Y = np.meshgrid(x, y)
Z = np.zeros_like(X)
for i in range(N):
for j in range(N):
Z[i, j] = f(torch.tensor(X[i, j]), torch.tensor(Y[i, j]))
ax.plot_surface(X, Y, Z, cmap='viridis')
ax.set_xlabel(f'$w_0$')
ax.set_ylabel(f'$w_1$')
ax.set_title(title)
def plot_contourf(ax, f, w_hist, color, title="", x_min=-5, x_max=5, y_min=-5, y_max=5, N=50, **kw):
x = np.linspace(x_min, x_max, N)
y = np.linspace(y_min, y_max, N)
X, Y = np.meshgrid(x, y)
Z = np.zeros_like(X)
for i in range(N):
for j in range(N):
Z[i, j] = f(torch.tensor(X[i, j]), torch.tensor(Y[i, j]))
for t in range(1, len(w_hist)):
ax.plot([w_hist[t-1][0], w_hist[t][0]], [w_hist[t-1][1], w_hist[t][1]], color=color)
ax.contourf(X, Y, Z, levels=20, cmap='viridis')
ax.scatter(w_hist[:, 0], w_hist[:, 1], marker='o', s=5, facecolors=color, color=color, **kw)
ax.set_title(title)
ax.set_xlabel(f'$w_0$')
ax.set_ylabel(f'$w_1$')
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111, projection='3d')
plot_surface(ax, pathological_loss, x_min=-5, x_max=5, y_min=-100, y_max=10, title="loss surface")

The following optimization algorithm purely operates on the loss surface as a function of weights.
It starts with initial weights w_init, then updates this weight iteratively by computing the
gradient of the loss function (which constructs a computational graph). The weight update step
depends on the particular optimizer class used.
def train_curve(
optim: OptimizerBase,
optim_params: dict,
w_init=[5.0, 5.0],
loss_fn=pathological_loss,
num_steps=100
):
"""Return trajectory of optimizer through loss surface from init point."""
w_init = torch.tensor(w_init).float()
w = nn.Parameter(w_init, requires_grad=True)
optim = optim([w], **optim_params)
points = [torch.tensor([w[0], w[1], loss_fn(w[0], w[1])])]
for step in range(num_steps):
optim.zero_grad()
loss = loss_fn(w[0], w[1])
loss.backward()
optim.step()
# logging
with torch.no_grad():
z = loss.unsqueeze(dim=0)
points.append(torch.cat([w.data, z]))
return torch.stack(points, dim=0).numpy()
Gradient descent from the same initial point with different learning rates:
Show code cell source
def plot_gd_steps(ax, optim, optim_params: dict, label_map={}, w_init=[-2.5, 2.5], num_steps=300, **plot_kw):
label = optim.__name__ + " (" + ", ".join(f"{label_map.get(k, k)}={v}" for k, v in optim_params.items()) + ")"
path = train_curve(optim, optim_params, w_init=w_init, num_steps=num_steps)
plot_contourf(ax[0], f=pathological_loss, w_hist=path, x_min=-10, x_max=10, y_min=-10, y_max=10, label=label, zorder=2, **plot_kw)
ax[1].plot(np.array(path)[:, 2], label=label, color=plot_kw.get("color"), zorder=plot_kw.get("zorder", 1))
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].grid(linestyle="dotted", alpha=0.8)
return path
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
plot_gd_steps(ax, optim=GD, optim_params={"lr": 3.0}, w_init=[-4.0, 5.0], label_map={"lr": r"$\eta$"}, color="red")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 1.0}, w_init=[-4.0, 5.0], label_map={"lr": r"$\eta$"}, color="black")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.1}, w_init=[-4.0, 5.0], label_map={"lr": r"$\eta$"}, color="blue")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[0].legend()
ax[1].legend();

The direction of steepest descent does not always point to the minimum. Depending on the learning rate, it can oscillate around a minimum, or it can get stuck in a flat region of the surface.
Loss landscape#
For convex functions, gradient descent has strong guarantees of converging. However, the loss surface of neural networks are generally nonconvex. Clever dimensionality reduction techniques allow us to visualize loss function curvature despite the very large number of parameters (Fig. 19 from [LXTG17]). Notice that there are plateaus (or flat minimas) and local minimas which makes gradient descent hard. In high-dimension saddle points are the most common critical points.
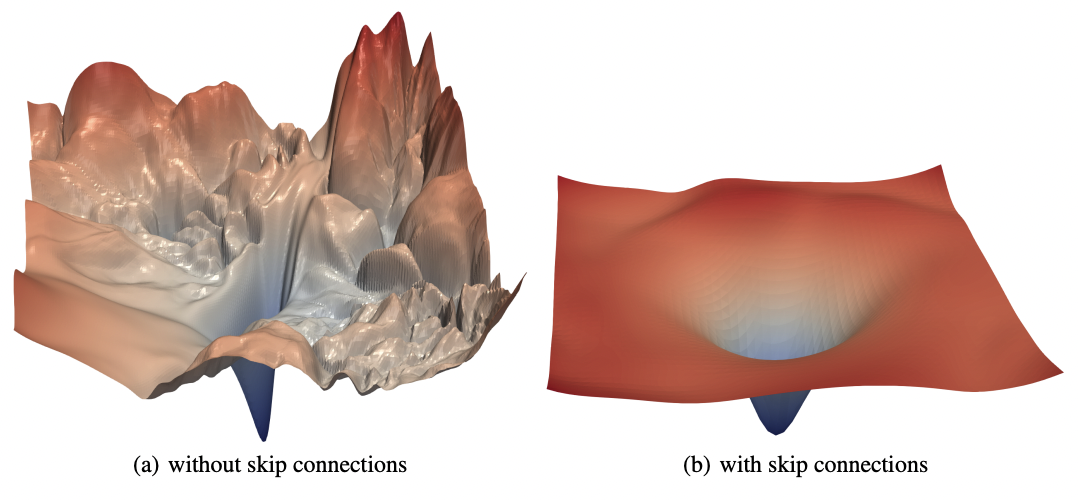
Fig. 19 The loss surfaces of ResNet-56 with (right) and without (left) skip connections. The loss surface on the right looks better although there are still some flatness. [LXTG17]#
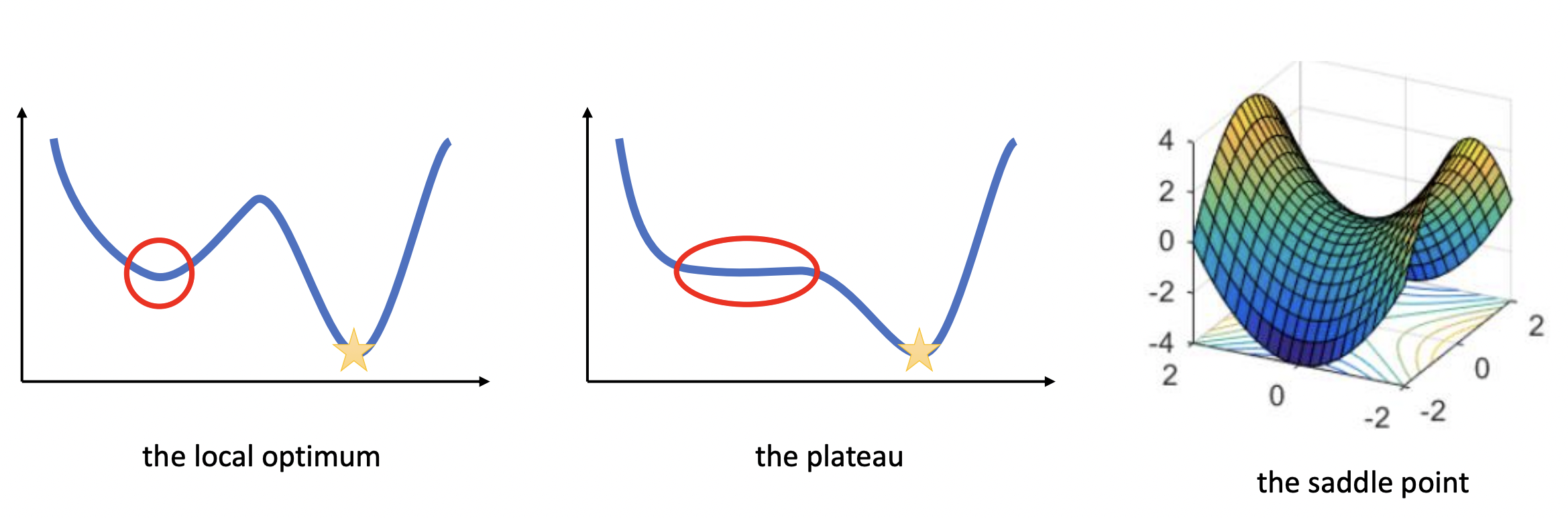
Fig. 20 Types of critical points. Source: [CS182-lec4]#
Local minima#
Local minimas are very scary, in principle, since gradient descent could converge to a solution that is arbitrarily worse than the global optimum. Surprisingly, this becomes less of an issue as the number of parameters increases, as they tend to be not much worse than global optima. Fig. 21 below shows that for larger networks the test loss variance between training runs become smaller. This indicates that local minima tend to be increasingly equivalent as we increase network size.
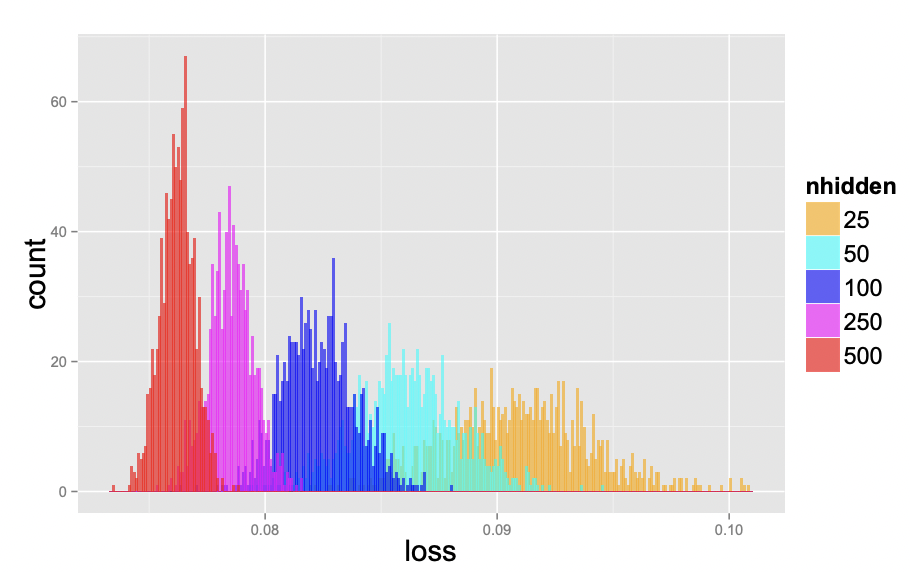
Fig. 21 Test loss of 1000 networks on a scaled-down version of MNIST, where each image was downsampled to size 10×10. The networks have one hidden layer and with 25, 50, 100, 250, and 500 hidden units, each one starting from a random set of parameters sampled uniformly within the unit cube. All networks were trained for 200 epochs using SGD with learning rate decay. Source: [CHM+15]#
Plateaus#
Plateaus are regions in the loss landscape with small gradients. It can also be a flat local minima. Below the initial weights is in a plateau, and the optimizer with small learning rate gets stuck and fails to converge. Large learning rate allows the optimizer to escape such regions. So we cannot just choose small learning rate to prevent oscillations. We will see later that momentum helps to overcome this tradeoff.
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.1}, w_init=[-4.0, 6.0], label_map={"lr": r"$\eta$"}, color="red")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.1}, w_init=[-4.0, -6.0], label_map={"lr": r"$\eta$"}, color="blue")
ax[1].set_ylim(0, 3)
ax[0].legend()
ax[1].legend();

Saddle points#
Saddle points are critical points (i.e. gradient zero) that are local minimum in some dimensions but local maximum in other dimensions. Neural networks have a lot of symmetry which can result in exponentially many local minima. Saddle points naturally arise in paths that connect these local minima (Fig. 22). It takes a long time to escape a saddle point since it is usually surrounded by high-loss plateaus [DPG+14]. A saddle point looks like a special structure. But in high-dimension, it turns out that most optima are saddle points.
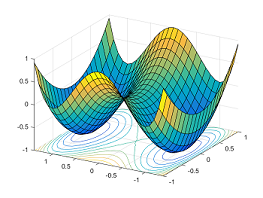
Fig. 22 Paths between two minimas result in a saddle point. Source: [offconvex.org]#
The Hessian \(\boldsymbol{\mathsf{H}}\) at the critical point of a surface is a matrix containing second derivatives at that point. We will see shortly that these characterize the local curvature. From Schwarz’s theorem, mixed partials are equal assuming the second partial derivatives are continuous around the optima. It follows that \(\boldsymbol{\mathsf{H}}\) is symmetric, and from the Real Spectral Theorem, \(\boldsymbol{\mathsf{H}}\) is diagonalizable with real eigenvalues. It turns out that local curvature is characterized by whether the eigenvalues are negative, zero, or positive.
If all eigenvalues of the Hessian are positive, it is positive-definite, i.e. \(\boldsymbol{\mathsf{x}}^\top \boldsymbol{\mathsf{H}}\, \boldsymbol{\mathsf{x}} > 0\) for \(\boldsymbol{\mathsf{x}} \neq \boldsymbol{0}.\) This follows directly from the spectral decomposition \(\boldsymbol{\mathsf{H}} = \boldsymbol{\mathsf{U}} \boldsymbol{\Lambda} \boldsymbol{\mathsf{U}}^\top\) such that \(\boldsymbol{\Lambda}\) is the diagonal matrix of eigenvalues of \(\boldsymbol{\mathsf{H}}\) and \(\boldsymbol{\mathsf{U}}\) is an orthogonal matrix with corresponding unit eigenvectors as columns. This is the multivariable equivalent of concave up. On the other hand, if all eigenvalues of \(\boldsymbol{\mathsf{H}}\) are negative, then it is negative-definite or concave down. To see this, observe that the Taylor expansion at the critical point is:
If any eigenvalue is zero, more information is needed (i.e. we need third order terms). Finally, if the eigenvalues are mixed, we get a saddle point where there are orthogonal directions corresponding to eigenvectors where the loss decreases and directions where the loss increases. Getting \(M = |\boldsymbol{\Theta}|\) eigenvalues of the same sign or having one zero eigenvalue is relatively rare for large networks with complex loss surfaces, so that the probability that the critical point is a saddle point is high.
Momentum methods#
Momentum#
Recall that high learning rate allows the optimizer to overcome plateaus. However, this can result in oscillation. The intuition behind momentum is that if successive gradient steps point in different directions, we should cancel off the directions that disagree. Moreover, if successive gradient steps point in similar directions, we should go faster in that direction. Simply adding gradients can result in extreme step size, so exponential averaging using a parameter \(0 \leq \beta < 1\) is used:
Note that \(\beta = 0\) is just regular GD.
In the following implementation, we add an extra parameter momentum=0.0 to the GD class for \(\beta\). Observe that the optimizer is now stateful: the attribute self.m stores the momentum vector \(\boldsymbol{\mathsf{m}}^t\) above as a dictionary with parameter keys. We will set \(\boldsymbol{\mathsf{m}}^0 = \boldsymbol{0}\) and \(\boldsymbol{\Theta}^1 = \boldsymbol{\Theta}_{\text{init}}.\)
class GD(OptimizerBase):
def __init__(self, params, lr, momentum=0.0):
super().__init__(params, lr)
self.beta = momentum
self.m = {p: torch.zeros_like(p.data) for p in self.params}
def update_param(self, p):
self.m[p] = self.beta * self.m[p] + (1 - self.beta) * p.grad
p += -self.lr * self.m[p]
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
label_map_gdm = {"lr": r"$\eta$", "momentum": r"$\beta$"}
plot_gd_steps(ax, optim=GD, optim_params={"lr": 3.0}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="red")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 3.0, "momentum": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="gray")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].grid(linestyle="dotted", alpha=0.8)
ax[0].legend()
ax[1].legend();

The optimizer is able to escape in initial plateau due to a high learning rate. Then, it overshoots resulting in delayed decrease in loss. Between roughly 60-80 steps, the optimizer escapes the lower plateau by accumulating small gradients toward the minimum. Finally, it oscillates around the minimum but these eventually die down due to the effect of momentum.
Remark. Momentum is aptly named since \(\beta\) can be thought of as the mass of a ball rolling down the surface to a minimum. It resists force (gradients), and maintains an inertia (momentum state vector) from previous updates.
RMSProp#
The relative magnitude of gradient is not very informative: only its sign is. Moreover, it changes during the course of training. Near the minimum it becomes small slowing down convergence. This makes it difficult to tune learning rate for different functions, or for different points on the same function. To fix this, RMSProp normalizes the gradient along each dimension. It estimates the size of the gradient using exponential averaging with \(\boldsymbol{\mathsf{v}}^0 = \mathbf{0}\) and \(\boldsymbol{\Theta}^1 = \boldsymbol{\Theta}_{\text{init}}\):
class RMSProp(OptimizerBase):
def __init__(self, params, lr, beta=0.9):
super().__init__(params, lr)
self.beta = beta
self.v = {p: torch.zeros_like(p.data) for p in self.params}
def update_param(self, p):
self.v[p] = self.beta * self.v[p] + (1 - self.beta) * p.grad ** 2
p += -self.lr * p.grad / torch.sqrt(self.v[p])
Notice that gradient normalization allows escaping plateaus:
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
label_map_rmsprop = {"lr": r"$\eta$", "beta": r"$\beta$"}
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.6}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="red")
plot_gd_steps(ax, optim=RMSProp, optim_params={"lr": 0.6, "beta": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_rmsprop, color="black")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].grid(linestyle="dotted", alpha=0.8)
ax[0].legend()
ax[1].legend();

The initial update has size \(\frac{\eta}{\sqrt{1 - \beta}} \geq \eta\) in each direction. Later if the current gradient is smaller than previous gradients, then the current update suddenly becomes small. This can be seen near the minimum. Conversely, if the current gradient is relatively larger than previous updates, then \(\frac{1}{\sqrt{\boldsymbol{\mathsf{v}}^{t}}} \nabla_{\boldsymbol{\Theta}}\, f(\boldsymbol{\Theta}^{t})\) is large. This again can be observed in the latter part of the training, after the steps become small in the minimum.
Remark. RMSProp have erratic properties, nevertheless it exhibits adaptive learning rates. That is, it looks like regular gradient descent but with dynamic effective learning rate in each parameter direction. Adam discussed next uses this and improves upon the defects of RMSProp.
Adam#
Notice that RMSProp experiences oscillations around the minimum. Adam [KB15] fixes this by combining momentum with RMSProp. Adam also uses bias correction so that gradients dominate during early stages of training instead of the state vectors which are initially set to zero. Let \(0 \leq \beta_1 < 1\), \(0 \leq \beta_2 < 1\), and \(0 < \epsilon \ll 1.\) Set \(\boldsymbol{\mathsf{m}}^0 = \boldsymbol{\mathsf{v}}^0 = \mathbf{0}\) and \(\boldsymbol{\Theta}^1 = \boldsymbol{\Theta}_{\text{init}}.\) Starting with \(t = 1\):
The set of parameters is \(\eta = 0.001\), \(\beta_1 = 0.9\), \(\beta_2 = 0.999\) and \(\epsilon = 10^{-8}\) is a good starting point. Here we choose \(\beta_2 > \beta_1\) since gradient magnitude usually does not change as fast as its direction so we choose a larger momentum. Note that similar to RMSProp, the update size autotunes, so that the learning rate \(\eta\) is roughly indicative of the update size.
Bias correction. Let \(\boldsymbol{\mathsf{g}}^t = \nabla_{\boldsymbol{\Theta}}\, f(\boldsymbol{\Theta}^{t}).\) Note that time \(t = 1\) corresponds to the initial point in the loss surface where \(\boldsymbol{\mathsf{g}}^1 = \nabla_{\boldsymbol{\Theta}}\, f(\boldsymbol{\Theta}_{\text{init}})\). This also means that \(t\) is the number of gradients that are summed when computing the exponential average. Observe that
This slows down training at early steps where the terms in the sum are few, so that \(\boldsymbol{\mathsf{m}}^t\) is small. Recall that \((1 - {\beta_1}^{3}) = (1 - {\beta_1}) \sum_{t = 0}^2 {\beta_1}^t.\) Dividing with this gets us a proper average that is biased towards recent gradients:
This calculation extends inductively. For \(t = 1\), \(\boldsymbol{\mathsf{m}}^1 = (1 - \beta_1)\,\boldsymbol{\mathsf{g}}^1\) whereas with bias correction we get \(\hat{\boldsymbol{\mathsf{m}}}^1 = \boldsymbol{\mathsf{g}}^1.\) The following implementation gets this right with self.t[p] = 1 at the initial point. Note that bias correction in momentum only works because of the auto-learning rate tuning with \(1 / \sqrt{\hat{\boldsymbol{\mathsf{v}}}^t}\). Otherwise, the optimizer rolls down a slope too fast, missing the minimum!
class Adam(OptimizerBase):
def __init__(self, params, lr=0.001, beta1=0.9, beta2=0.999, eps=1e-8):
super().__init__(params, lr)
self.beta1 = beta1
self.beta2 = beta2
self.m = {p: torch.zeros_like(p.data) for p in self.params}
self.v = {p: torch.zeros_like(p.data) for p in self.params}
self.t = {p: 0 for p in self.params} # Params are updated one by one.
self.eps = eps
def update_param(self, p):
self.t[p] += 1
self.m[p] = self.beta1 * self.m[p] + (1 - self.beta1) * p.grad
self.v[p] = self.beta2 * self.v[p] + (1 - self.beta2) * p.grad ** 2
m_hat = self.m[p] / (1 - self.beta1 ** self.t[p])
v_hat = self.v[p] / (1 - self.beta2 ** self.t[p])
p += -self.lr * m_hat / (torch.sqrt(v_hat) + self.eps)
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
label_map_adam = {"lr": r"$\eta$", "beta1": r"$\beta_1$", "beta2": r"$\beta_2$"}
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.3}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="red")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 0.3, "momentum": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="gray")
plot_gd_steps(ax, optim=Adam, optim_params={"lr": 0.3, "beta1": 0.9, "beta2": 0.999}, w_init=[-4.0, 5.0], label_map=label_map_adam, color="blue")
plot_gd_steps(ax, optim=RMSProp, optim_params={"lr": 0.3, "beta": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_rmsprop, color="black")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].grid(linestyle="dotted", alpha=0.8)
ax[0].legend()
ax[1].legend();

The effect of momentum in Adam can be seen by the dampening of oscillations. Observe that for RMSProp, the oscillations do not die out near the minimum. Moreover, at the start of training where gradient updates do not cancel out, Adam has a step size of \(\eta\) in each direction. Then adaptive learning rate helps to regulate the step size as the gradient tends to zero around the minimum.
Trying out a larger learning rate:
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
plot_gd_steps(ax, optim=GD, optim_params={"lr": 2.5}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="red")
plot_gd_steps(ax, optim=GD, optim_params={"lr": 2.5, "momentum": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="gray")
plot_gd_steps(ax, optim=Adam, optim_params={"lr": 2.5, "beta1": 0.9, "beta2": 0.999}, w_init=[-4.0, 5.0], label_map=label_map_adam, color="blue")
plot_gd_steps(ax, optim=RMSProp, optim_params={"lr": 2.5, "beta": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_rmsprop, color="black")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].grid(linestyle="dotted", alpha=0.8)
ax[0].legend()
ax[1].legend();

Adam converges faster than GD since the update step, like RMSProp, is not as dependent on the magnitude of the gradient. However, the loss with Adam fluctuates a bit near the end of training. This can be attributed to the oscillations changing orientation, since the step size does not stabilize to zero. This is consistent with folk knowledge that SGD with momentum (see below), if tuned well and given enough time to converge, performs better than Adam. This is discussed further below.
Remark. Note that the gradient is coupled with the averaging technique in Adam. If we include regularization or weight decay in the loss, this means weight decay is likewise coupled. This is fixed in AdamW [LH17] which adjusts the weight decay term to appear in the gradient update:
where \(\lambda^t\) is the weight decay term at time \(t.\) See AdamW implementation in PyTorch.
SGD#
Gradient descent computes gradients for each instance in the training set. This can be expensive for large datasets. Note that can take a random subset \(\mathcal{B} \subset \mathcal{D}\) such that \(B = |\mathcal{B}| \ll |\mathcal{D}|\) and still get an unbiased estimate \(\mathcal{L}_{\mathcal{B}} \approx \mathcal{L}_\mathcal{D}\) of the empirical loss surface. This method is called Stochastic Gradient Descent (SGD). This makes sense since \(\mathcal{L}_\mathcal{D}\) is also an estimate of the true loss surface that is fixed at each training step. SGD a lot cheaper to compute compared to batch GD allowing training to progress faster with more updates. Moreover, SGD has been shown to escape saddle points with some theoretical guarantees [DPG+14]. The update rule for SGD is given by:
Typically, we take \(B = 8, 32, 64, 128, 256.\) Note that SGD is essentially GD above it just replaces the function \(f\) at each step with \(\mathcal{L}_{\mathcal{B}}.\) Hence, all modifications of GD discussed have the same update rule for SGD. The same results and observations also mostly hold. Although, now we have to reason with noisy approximations \(f_t \approx f\) at each step unlike before where it is fixed.
Show code cell source
from functools import partial
def loss(w0, w1, X, y):
return ((X @ np.array([w0, w1]) - y)**2).mean()
def grad(w, X, y, B=None):
"""Gradient step for the MSE loss function"""
dw = 2*((X @ w - y).reshape(-1, 1) * X).mean(axis=0)
return dw / np.linalg.norm(dw)
def sgd(w0, X, y, eta=0.1, steps=10, B=32):
"""Return sequence of weights from GD."""
w = np.zeros([steps, 2])
w[0, :] = w0
for j in range(1, steps):
batch = torch.randint(0, len(X), size=(B,))
u = w[j-1, :]
w[j, :] = u - eta * grad(u, X[batch], y[batch])
return w
# Generate data
B = 4
n = 1000
X = np.zeros((n, 2))
X[:, 1] = np.random.uniform(low=-1, high=1, size=n)
X[:, 0] = 1
w_min = np.array([-1, 3])
y = (X @ w_min) + 0.05 * np.random.randn(n) # data: y = -1 + 3x + noise
# Gradient descent
w_init = [-4, -4]
w_step_gd = sgd(w_init, X, y, eta=0.5, steps=30, B=len(X))
w_step_sgd = sgd(w_init, X, y, eta=0.5, steps=30, B=B)
# Create a figure and two subplots
fig = plt.figure(figsize=(12, 11))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223, projection='3d')
ax4 = fig.add_subplot(224, projection='3d')
# Call the functions with the respective axes
plt.tight_layout()
plot_contourf(ax1, partial(loss, X=X, y=y), w_step_gd, color="red")
plot_contourf(ax2, partial(loss, X=X, y=y), w_step_sgd, color="red")
plot_surface(ax3, partial(loss, X=X, y=y), N=50)
for i in range(5):
batch = torch.randint(0, len(X), size=(B,))
plot_surface(ax4, f=partial(loss, X=X[batch], y=y[batch]), N=50)
ax1.set_title("GD")
ax2.set_title(f"SGD (B={B})")
ax3.set_title("\nloss surface")
ax4.set_title(f"\nloss approx. (B={B})")
fig.tight_layout()
plt.show()

Remark. Randomly sampling from \(N \gg 1\) points at each step is expensive. Instead, we typically just shuffle the dataset once, then iterate over it with slices of size \(B\). This is essentially sampling without replacement which turns out that this is more data efficient (i.e. the model gets to see more varied data). One such pass over the dataset is called an epoch. This is done for example when using PyTorch DataLoaders:
from torch.utils.data import DataLoader
train_loader = DataLoader(torch.arange(10), batch_size=2, shuffle=True)
print("Epoch 1:")
[print(x) for x in train_loader]
print()
print("Epoch 2:")
[print(x) for x in train_loader];
Epoch 1:
tensor([7, 8])
tensor([5, 4])
tensor([0, 6])
tensor([2, 9])
tensor([1, 3])
Epoch 2:
tensor([6, 3])
tensor([7, 5])
tensor([9, 8])
tensor([4, 2])
tensor([0, 1])
Hyperparameters#
Batch size#
Folk knowledge tells us to set powers of 2 for batch size \(B = 16, 32, 64, ..., 512.\) Starting with \(B = 32\) is recommended for image tasks [ML18]. Note that we may need to train with large batch sizes depending on the network architecture, the nature of the training distribution, or if we have large compute [GDG+17]. Conversely, we may be forced to use small batches due to resource constraints with large models.
Large batch. Increasing \(B\) with other parameters fixed can result in worse generalization (Fig. 23). This has been attributed to large batch size decreasing gradient noise [GZR21]. Intuitively, less sampling noise means that we can use a larger learning rate. Indeed, [GDG+17] suggests scaling up the learning rate by the same factor that we increase batch size (Fig. 25).
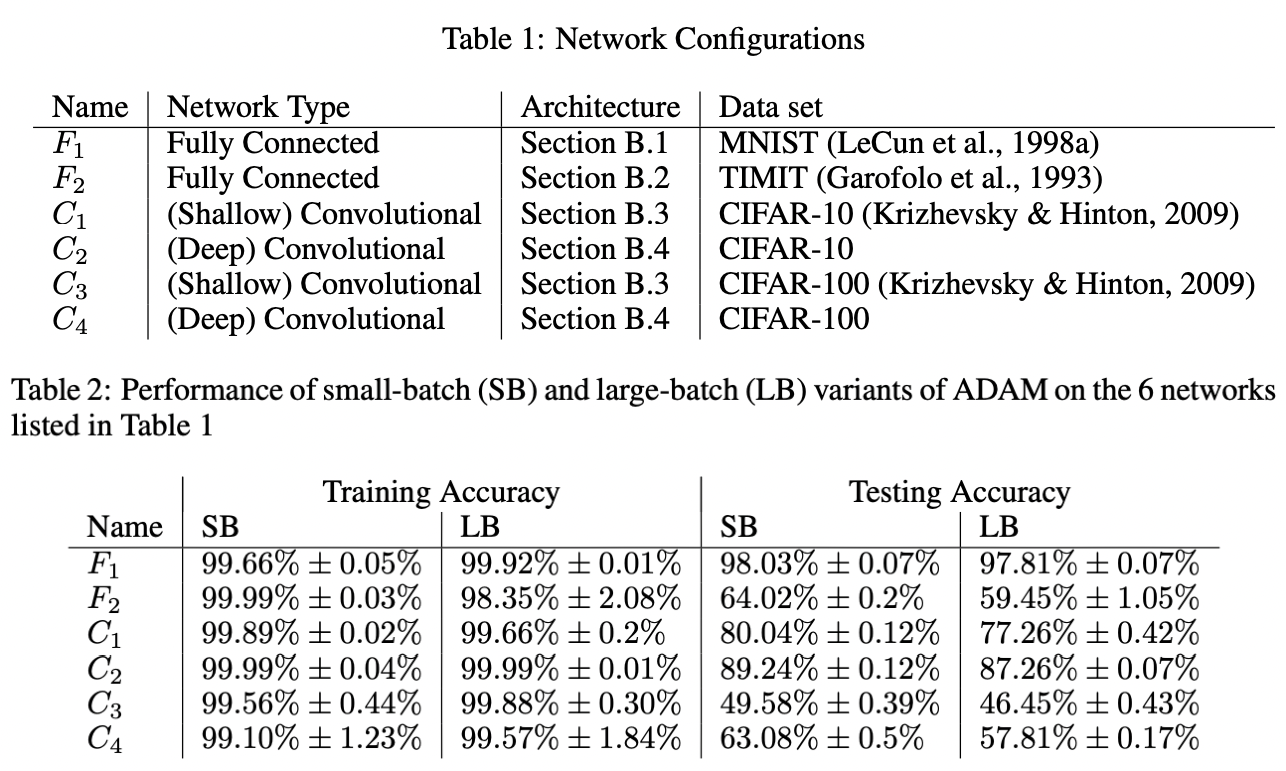
Fig. 23 [KMN+16b] All models are trained in PyTorch using Adam with default parameters. Large batch training (LB) uses 10% of the dataset while small batch (SB) uses \(B = 256\). Recall that generalization gap reflects model bias and therefore is generally a function of network architecture. The table shows results for models that were not overfitted to the training distribution.#
Small batch. This generally results in slow and unstable convergence since the loss surface is poorly approximated at each step. This is fixed by gradient accumulation which simulates a larger batch size by adding gradients from multiple small batches before performing a weight update. Here accumulation step is increased by the same factor that batch size is decreased. This also means training takes longer by roughly the same factor.
for i, batch in enumerate(train_loader):
x, y = batch
outputs = model(x)
loss = loss_fn(y, outputs) / accumulation_steps
loss.backward()
if i % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Remark. GPU is underutilized when \(B\) is small, and we can get OOM when \(B\) is large.
In general, hardware constraints should be considered in parallel with theory.
GPU can idle if there is lots of CPU processing on a large batch, for example. One can set
pin_device=True can be set in the data loader to speed up data transfers to
the GPU by leveraging page locked memory.
Similar tricks
(Fig. 24) have to be tested empirically to see whether it works on your
use-case. These are hard to figure out based on first principles.
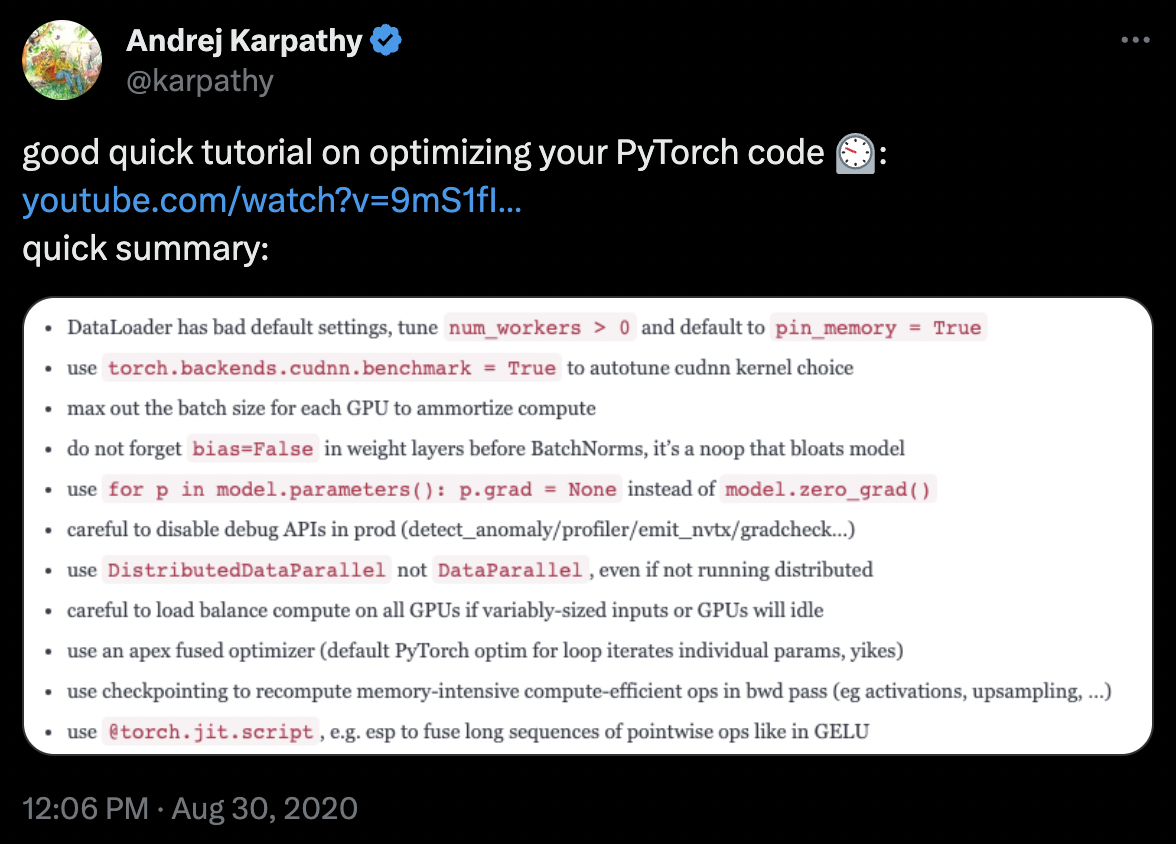
Fig. 24 A tweet by Andrej Karpathy on tricks to optimize Pytorch code. The linked video.#
Learning rate#
Finding an optimal learning rate is essential for both better performance and faster convergence. This is true even for optimizers (like Adam) that have adaptive learning rates based on our experiments. As discussed earlier, the choice of learning rate depends on the batch size. If we find a good base learning rate and want to change the batch size, we have to scale the learning rate with the same factor [GDG+17] [GZR21]. This means smaller learning rate for smaller batches, and vice-versa (Fig. 25).
In practice, we start with setting an appropriate batch size since this depends on constraints such as GPU efficiency and CPU processing code and implementation, as well as data transfer latency. Then, proceed with configuring learning rate tuning (i.e. choice of base learning rate and LR decay policy) discussed in this section.
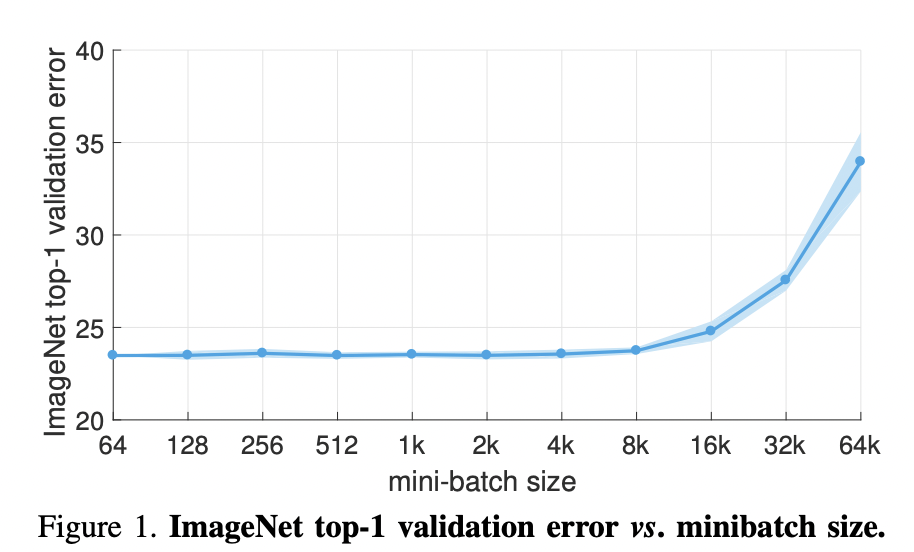
Fig. 25 From [GDG+17]. For all experiments \(B \leftarrow aB\) and \(\eta \leftarrow a\eta\) sizes are set. Note that a simple warmup phase for the first few epochs of training until the learning rate stabilizes to \(\eta\) since early steps are away from any minima, hence can be unstable. All other hyper-parameters are kept fixed. Using this simple approach, accuracy of our models is invariant to minibatch size (up to an 8k minibatch size). As an aside the authors were able to train ResNet-50 on ImageNet in 1 hour using 256 GPUs. The scaling efficiency they obtained is 90% relative to the baseline of using 8 GPUs.#
LR finder. The following is a parameter-free approach to finding a good base learning rate. The idea is to select a base learning rate that is as large as possible without the loss diverging at early steps of training. This allows the optimizer to initially explore the surface with less risk of getting stuck in plateaus.
num_steps = 1000
lre_min = -2.0
lre_max = 0.6
lre = torch.linspace(lre_min, lre_max, num_steps)
lrs = 10 ** lre
w = nn.Parameter(torch.FloatTensor([-4.0, -4.0]), requires_grad=True)
optim = Adam([w], lr=lrs[0])
losses = []
for k in range(num_steps):
optim.lr = lrs[k] # (!) change LR at each step
optim.zero_grad()
loss = pathological_loss(w[0], w[1])
loss.backward()
optim.step()
losses.append(loss.item())
Show code cell source
plt.figure(figsize=(6, 3.5))
plt.plot(lrs.detach(), losses)
plt.xlabel("learning rate")
plt.ylabel("loss")
plt.grid(linestyle='dotted')
plt.axvline(2.5, color='k', linestyle='dashed', label='base LR')
plt.legend();

Notice that sampling is biased towards small learning rates. This makes sense since large learning rates tend to diverge. The graph is not representative for practical problems since the network is small and the loss surface is relatively simple. But following the algorithm, lr=2.0 may be chosen as the base learning rate.
LR scheduling. Learning rate has to be decayed to later help with convergence. The following modifies the training script to include a simple schedule. Repeating the same experiment above for RMSProp and GD which had issues with oscillation:
def train_curve(
optim: OptimizerBase,
optim_params: dict,
w_init=[5.0, 5.0],
loss_fn=pathological_loss,
num_steps=100
):
"""Return trajectory of optimizer through loss surface from init point."""
w_init = torch.tensor(w_init).float()
w = nn.Parameter(w_init, requires_grad=True)
optim = optim([w], **optim_params)
points = [torch.tensor([w[0], w[1], loss_fn(w[0], w[1])])]
for step in range(num_steps):
optim.zero_grad()
loss = loss_fn(w[0], w[1])
loss.backward()
optim.step()
# logging
with torch.no_grad():
z = loss.unsqueeze(dim=0)
points.append(torch.cat([w.data, z]))
# LR schedule (!)
if step % 70 == 0:
optim.lr *= 0.5
return torch.stack(points, dim=0).numpy()
Show code cell source
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
plot_gd_steps(ax, optim=GD, optim_params={"lr": 3.0}, w_init=[-4.0, 5.0], label_map=label_map_gdm, color="red")
plot_gd_steps(ax, optim=RMSProp, optim_params={"lr": 3.0, "beta": 0.9}, w_init=[-4.0, 5.0], label_map=label_map_rmsprop, color="black")
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-7, 7)
ax[1].set_xlabel("steps")
ax[1].set_ylabel("loss")
ax[1].axvline(70, linestyle='dashed')
ax[1].axvline(140, linestyle='dashed')
ax[1].axvline(210, linestyle='dashed', label='LR step', zorder=1)
ax[1].grid(linestyle="dotted", alpha=0.8)
ax[0].legend()
ax[1].legend();

Learning rate decay decreases GD oscillation drastically. The schedule \(\boldsymbol{\boldsymbol{\Theta}}^{t+1} = \boldsymbol{\boldsymbol{\Theta}}^{t} - \eta \frac{1}{\alpha^t} \, \boldsymbol{\mathsf{m}}^{t}\) where \(\alpha^t = 2^{\lfloor t / 100 \rfloor}\) is known as step LR decay. Note that this augments the second-moment for RMSProp which already auto-tunes the learning rate. Here we are able to start with a large learning rate allowing the optimizer to escape the first plateau earlier than before. Note that decay only decreases learning rate which can cause slow convergence. Some schedules implement warm restarts to fix this (Fig. 26).
Remark. For more examples of learning rate decay schedules see here (e.g. warmup which initially gradually increases learning rate
since SGD at initialization can be unstable with large LR). Also see PyTorch docs on LR schedulers implemented in the library. For example, the schedule reduce LR on plateau which reduces the learning rate when a metric has stopped improving is implemented in PyTorch as ReduceLROnPlateau in the torch.optim.lr_scheduler library.
# Example: PyTorch code for chaining LR schedulers
optim = SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler1 = ExponentialLR(optim, gamma=0.9)
scheduler2 = MultiStepLR(optim, milestones=[30,80], gamma=0.1)
for epoch in range(10):
for x, y in dataset:
optim.zero_grad()
loss = loss_fn(model(x), y)
loss.backward()
optim.step()
# LR step called after optimizer update! ⚠⚠⚠
scheduler1.step()
scheduler2.step()
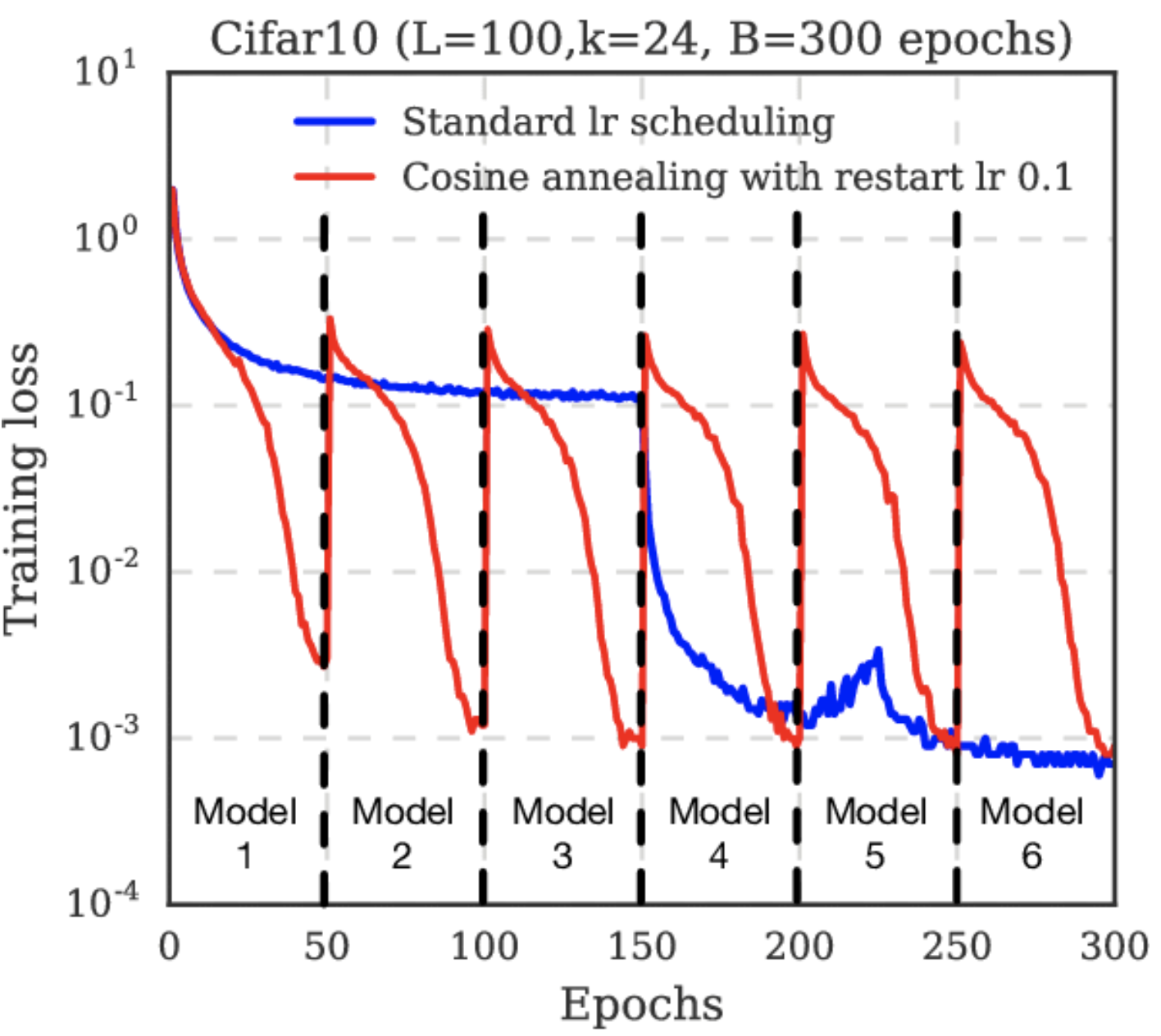
Fig. 26 Cosine annealing starts with a large learning rate that is relatively rapidly decreased to a minimum value before being increased rapidly again. This resetting acts like a simulated restart of the model training and the re-use of good weights as the starting point of the restart is referred to as a “warm restart” in contrast to a “cold restart” at initialization. Source: [LH16]#
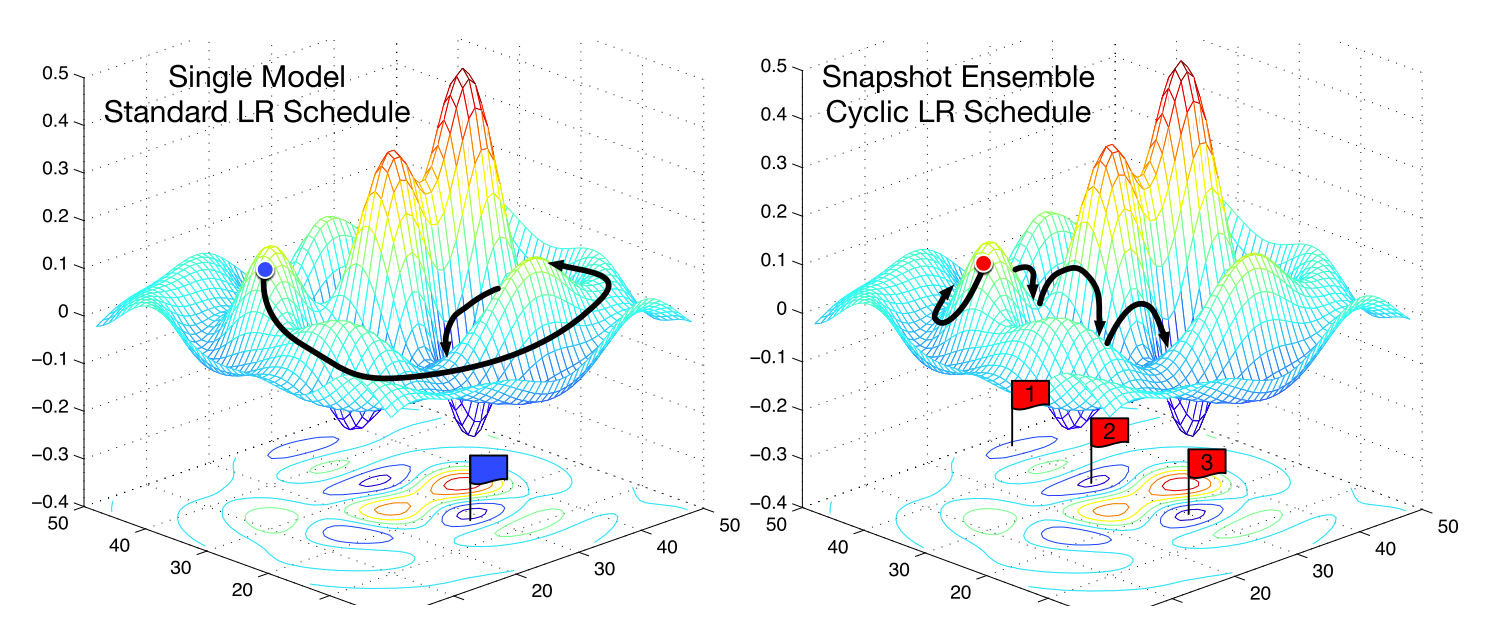
Fig. 27 Effect of cyclical learning rates. Each model checkpoint for each LR warm restart (which often correspond to a minimum) can be used to create an ensemble model. Source: [HLP+17]#
Momentum#
Good starting values for SGD momentum are \(\beta = 0.9\) or \(0.99\). Adam is easier to use out of the box where we like to keep the default parameters. If we have resources, and we want to push test performance, we can tune SGD which is known to generalize better than Adam with more epochs. See [ZFM+20] where it is shown that Adam is more stable at sharp minima which tend to generalize worse than flat ones (Fig. 28).
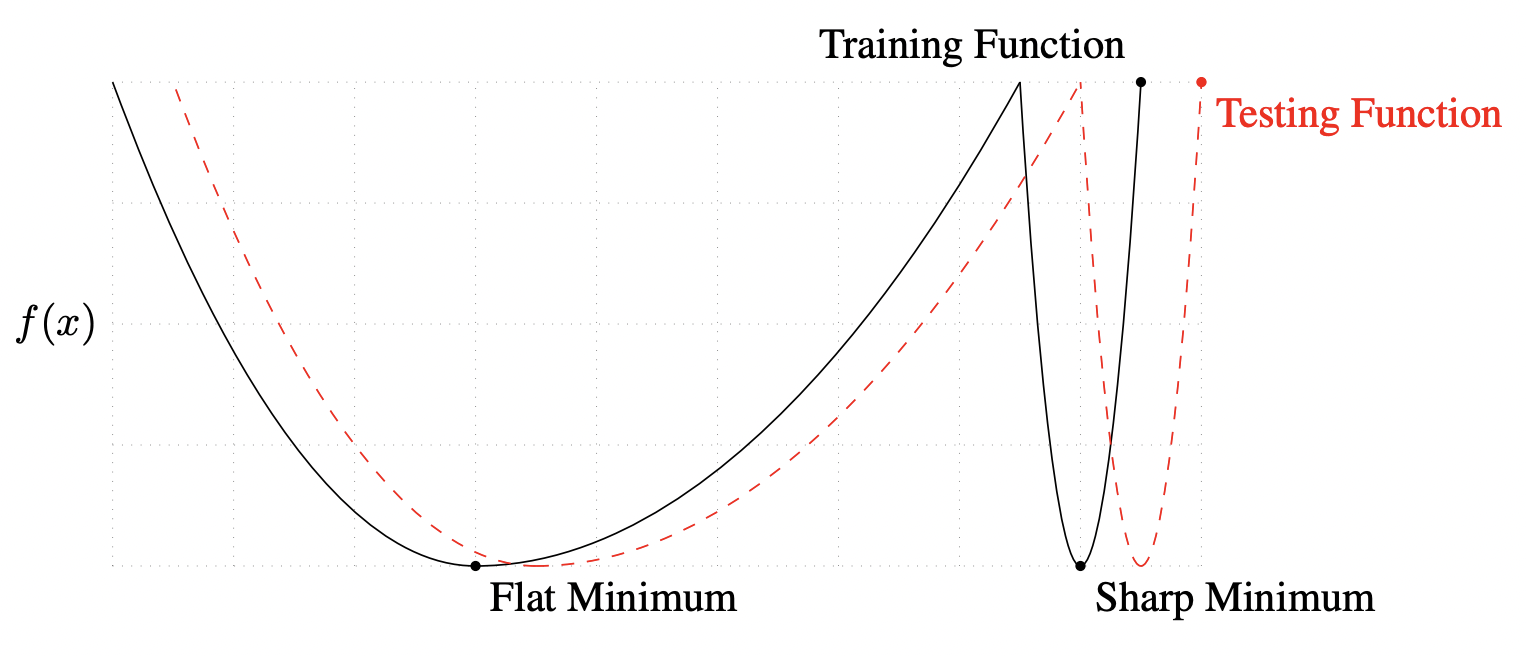
Fig. 28 A conceptual sketch of flat and sharp minima. The Y-axis indicates value of the loss function and the X-axis the variables. Source: [KMN+16b]#
Remark. In principle, optimization hyperparameters affect training and not generalization. But the situation is more complex with SGD, where stochasticity contributes to regularization. This was shown above where choice of batch size influences the generalization gap. Also recall that for batch GD (i.e. \(B = N\) in SGD), consecutive gradients approaching a minimum roughly have the same direction. This should not happen with SGD with \(B \ll N\) in the learning regime as different samples will capture different aspects of the loss surface. Otherwise, the network is starting to overfit. Hence, optimization hyperparameters are tuned on the validation set as well in practice.
■