Language Modeling#



Readings: [ZLLS21] karpathy/makemore
Introduction#
In this notebook, we introduce a character-level language model. This model can be used to generate new names using an autoregressive Markov process after learning from a dataset of names. Our focus will be on introducing the overall framework of language modeling that includes probabilistic modeling and optimization. This notebook draws on relevant parts of this lecture series.
Names dataset#
import math
import torch
import random
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
from matplotlib_inline import backend_inline
DATASET_DIR = Path("./data").absolute()
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
warnings.simplefilter(action="ignore")
backend_inline.set_matplotlib_formats("svg")
Downloading the dataset:
import os
if not os.path.isfile("./data/surnames_freq_ge_100.csv"):
!wget -O ./data/surnames_freq_ge_100.csv https://raw.githubusercontent.com/particle1331/spanish-names-surnames/master/surnames_freq_ge_100.csv
!wget -O ./data/surnames_freq_ge_20_le_99.csv https://raw.githubusercontent.com/particle1331/spanish-names-surnames/master/surnames_freq_ge_20_le_99.csv
else:
print("Data files already exist.")
col = ["surname", "frequency_first", "frequency_second", "frequency_both"]
df1 = pd.read_csv(DATASET_DIR / "surnames_freq_ge_100.csv", names=col, header=0)
df2 = pd.read_csv(DATASET_DIR / "surnames_freq_ge_20_le_99.csv", names=col, header=0)
Show code cell output
Data files already exist.
FRAC_LIMIT = 0.30
df = pd.concat([df1, df2], axis=0)[["surname"]].sample(frac=FRAC_LIMIT)
df = df.reset_index(drop=True)
df["surname"] = df["surname"].map(lambda s: s.lower())
df["surname"] = df["surname"].map(lambda s: s.replace("de la", "dela"))
df["surname"] = df["surname"].map(lambda s: s.replace(" ", "_"))
df = df[["surname"]].dropna().astype(str)
names = [
n for n in df.surname.tolist()
if ("'" not in n) and ('ç' not in n) and (len(n) >= 2)
]
for j in range(5):
print(names[j])
durana
dela_azuela
atlassi
irulegi
stockwell
All characters:
s = set(c for n in names for c in n)
chars = "".join(sorted(list(s)))
NUM_CHARS = len(chars)
print(chars)
print(NUM_CHARS)
_abcdefghijklmnopqrstuvwxyzñ
28
Show code cell source
from collections import Counter
length_count = Counter([len(n) for n in names])
char_count = Counter("".join(names))
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
ax[0].bar(length_count.keys(), length_count.values())
ax[0].set_xlabel("name length", fontsize=10)
ax[0].set_ylabel("count", fontsize=10)
keys = sorted(char_count.keys())
ax[1].set_ylabel("count")
ax[1].set_xlabel("characters")
ax[1].bar(keys, [char_count[k] for k in keys], color="C1")
fig.tight_layout()

Range of name lengths:
print("min:", min(length_count.keys()))
print("max:", max(length_count.keys()))
print("median:", int(np.median(sorted([len(n) for n in names]))))
min: 2
max: 25
median: 7
Names as sequences#
A name is technically a sequence of characters. The primary task of language modeling is to assign probabilities to sequences. Recall that we can write a joint distribution as a chain of conditional distributions:
In practice, we condition on a context consisting of previous characters \((\boldsymbol{\mathsf x}_{t-k+1}, \ldots, \boldsymbol{\mathsf x}_{t})\) of fixed size \(k\) to approximate the conditional probability of \(\boldsymbol{\mathsf x}_{t+1}.\)
This is due to architectural constraints in our models. For example, we can create input-output pairs for the name olivia with context size 2:
ol -> i
li -> v
iv -> a
These contexts are called trigrams. For context size 1, the pairs are called bigrams. In this notebook we will focus on bigrams, i.e. predicting the next character using a single character as context. And maybe look at how results improve by using a larger context.
Padding. Because our names are not infinite sequences, we have to model the start and end of names. We do this by introducing special characters for them and incorporating these into the dataset. For example:
[o -> l
li -> v
iv -> a
va -> ]
This way our models also learn how to start and end names. But observe that it suffices to use a single character . to indicate the start and end of a name. Sort of like a record button is pressed twice to record the characters.
.. -> o
ol -> i
li -> v
iv -> a
va -> .
Note that we use two dots (i.e. equal to the number of context) since we want the model to start from nothing to the first character.
Dataset class#
From the discussion above, we want to sample input-output pairs of each character and its context from names to model the conditional probabilities. This is implemented by the following class which builds all subsequences of characters \((\boldsymbol{\mathsf x}_{t-k+1}, \ldots,\boldsymbol{\mathsf x}_{t})\) of a name as input and the next character \(\boldsymbol{\mathsf x}_{t+1}\) as the corresponding target to form our character-level dataset.
For our purposes, the encoding simply maps characters to integers.
import torch
from torch.utils.data import Dataset
class CharDataset(Dataset):
def __init__(self, contexts: list[str], targets: list[str], chars: str):
self.chars = chars
self.ys = targets
self.xs = contexts
self.block_size = len(contexts[0])
self.itos = {i: c for i, c in enumerate(self.chars)}
self.stoi = {c: i for i, c in self.itos.items()}
def get_vocab_size(self):
return len(self.chars)
def __len__(self):
return len(self.xs)
def __getitem__(self, idx):
x = self.encode(self.xs[idx])
y = torch.tensor(self.stoi[self.ys[idx]]).long()
return x, y
def decode(self, x: torch.tensor) -> str:
return "".join([self.itos[c.item()] for c in x])
def encode(self, word: str) -> torch.tensor:
return torch.tensor([self.stoi[c] for c in word]).long()
def build_dataset(names, block_size=3):
"""Build word context -> next char target lists from names."""
xs = [] # context list
ys = [] # target list
for name in names:
context = ["."] * block_size
for c in name + ".":
xs.append(context)
ys.append(c)
context = context[1:] + [c]
chars = sorted(list(set("".join(ys))))
return CharDataset(contexts=xs, targets=ys, chars=chars)
Using this we can create sequence datasets of arbitrary context size.
dataset = build_dataset(names, block_size=3)
xs = []
ys = []
for i in range(7):
x, y = dataset[i]
xs.append(x)
ys.append(y)
pd.DataFrame({'x': [x.tolist() for x in xs], 'y': [y.item() for y in ys], 'x_word': ["".join(dataset.decode(x)) for x in xs], 'y_char': [dataset.itos[c.item()] for c in ys]})
| x | y | x_word | y_char | |
|---|---|---|---|---|
| 0 | [0, 0, 0] | 5 | ... | d |
| 1 | [0, 0, 5] | 22 | ..d | u |
| 2 | [0, 5, 22] | 19 | .du | r |
| 3 | [5, 22, 19] | 2 | dur | a |
| 4 | [22, 19, 2] | 15 | ura | n |
| 5 | [19, 2, 15] | 2 | ran | a |
| 6 | [2, 15, 2] | 0 | ana | . |
Counting n-grams#
Bigrams can be thought of as input-output pairs with context size 1. An entry [i, j] in the array below is the count of bigrams that start with the ith character followed by the jth character. Recall that we use . to signify the start of a name which will be closed by another . to signify its end. Iterating over all names to get all existing bigrams:
names_train = names[:int(0.80 * len(names))]
names_valid = names[int(0.80 * len(names)):]
bigram_train = build_dataset(names_train, block_size=1)
bigram_valid = build_dataset(names_valid, block_size=1)
# Create count matrix
n = bigram_train.get_vocab_size()
N2 = torch.zeros((n, n), dtype=torch.int32)
for x, y in bigram_train:
N2[x[0].item(), y.item()] += 1
# Visualize count matrix
plt.figure(figsize=(18, 18))
plt.imshow(N2, cmap='Blues')
for i in range(N2.shape[0]):
for j in range(N2.shape[1]):
chstr = bigram_train.itos[i] + bigram_train.itos[j]
plt.text(j, i, chstr, ha="center", va="bottom", color="gray")
plt.text(j, i, N2[i, j].item(), ha="center", va="top", color="gray")
plt.axis("off");

Show code cell content
print(sum([int(n[0] == "a") for n in names_train]))
print(sum([int(n[-1] == "a") for n in names_train]))
1526
3864
Note distribution of targets (i.e. characters) are similar in train and validations sets:
Show code cell source
from collections import Counter
train_count = Counter(bigram_train.ys)
valid_count = Counter(bigram_valid.ys)
train_total = sum(train_count.values(), 0.0)
valid_total = sum(valid_count.values(), 0.0)
for k in train_count: train_count[k] /= train_total
for k in valid_count: valid_count[k] /= valid_total
plt.title("Target distribution")
plt.bar(*list(zip(*sorted(train_count.items()))), label="train")
plt.bar(*list(zip(*sorted(valid_count.items()))), alpha=0.5, label="valid")
plt.legend();

Generating names#
Already at this point we can generate names. Recall that we can write joint distributions as a chain of conditional probabilities. But that we condition only on limited context as a form of truncation or approximation. This process can also used as an algorithm to generate names.
First, a character is sampled given the start context (i.e. .. for trigrams). The context shifts by appending it with the last sampled character to sample a new one. For example, we adjust the context to .e after sampling e from ... This is repeated until we sample another . which indicates the end of a name.
def generate_names(model, dataset, sample_size, seed=2147483647):
"""Generate names from a Markov process with cond proba from model."""
g = torch.Generator().manual_seed(seed)
block_size = dataset.block_size
names = []
for _ in range(sample_size):
out = []
context = "." * block_size
while True:
x = torch.tensor(dataset.encode(context))[None, :]
j = torch.multinomial(model(x)[0], num_samples=1, replacement=True, generator=g).item()
if j == 0:
break
context = context[1:] + dataset.itos[j]
out.append(dataset.itos[j])
names.append("".join(out))
return names
Generating names from conditional distributions estimated by counting bigrams:
P2 = (N2 + 0.01) / (N2 + 0.01).sum(dim=1, keepdim=True)
for name in generate_names(lambda x: P2[tuple(x)], bigram_train, sample_size=12, seed=0):
print(name)
s
o
gaririliña
s
er
halabarzamigereñeba
doitan_mbamco
peso
cunaifroci
adenabide
ge
ejasaceceicoo
Trying out trigrams. Note smoothing for zero counts:
trigram_train = build_dataset(names_train, block_size=2)
trigram_valid = build_dataset(names_valid, block_size=2)
# Create count matrix
n = trigram_train.get_vocab_size()
N3 = torch.zeros((n, n, n), dtype=torch.int32)
for x, y in trigram_train:
N3[x[0].item(), x[1].item(), y.item()] += 1
P3 = (N3 + 0.01) / (N3 + 0.01).sum(dim=-1, keepdim=True)
for name in generate_names(lambda x: P3[tuple(x[0])][None, :], trigram_train, sample_size=12, seed=0):
print(name)
sa
elarreiroña
sala
halabbazamigengañandelitan_mez_coriescabon
eftocia
con
bidghipaijastenceijookhi
sansibaclino
motchailcaurbosanzamdar
anat
muz
ni
Remark. Names generated from bigrams look pretty bad, but still looks better than random. One straightforward way to improve this is to increase context size as we did above. But this solution does not scale to n-grams due to Zipf’s law where the next probable n-gram has a probability that drops exponentially from the last. Increasing the context size results in a longer tail.
fig, ax = plt.subplots(1, 1, figsize=(5, 3))
ax.plot(np.linspace(0, 1, N2.reshape(-1).shape[0]), sorted(N2.reshape(-1), reverse=True), label="bigrams")
ax.plot(np.linspace(0, 1, N3.reshape(-1).shape[0]), sorted(N3.reshape(-1), reverse=True), label="trigrams", color="C1")
ax.set_yscale("log")
ax.legend()
fig.tight_layout()

Model quality: NLL#
To measure model quality we use maximum likelihood estimation (MLE). That is, we choose model parameters \(\boldsymbol{\Theta}\) that maximizes the probability of the dataset. For our character-level language model, our objective will be to maximize the probability assigned by the model to the next character:
From the perspective of optimization, it is better to take the negative logarithm of the probability which is a positive function that increases rapidly as the probability goes to zero, and has a nonzero derivative even as the probability goes to 1. Hence, we take the resulting loss function called the negative log-likelihood which is equivalent to next-character MLE, but easier to optimize:
where \(n\) is the total number of characters to predict. Let us compute the NLL of the bigram model after fitting it on the counts. Note that bigram models assign probability using only the previous character, so that \(\,\hat p(\boldsymbol{\mathsf{x}}_{t} \mid \boldsymbol{\mathsf{x}}_1, \ldots, \boldsymbol{\mathsf{x}}_{t-1}; \boldsymbol{\Theta}) = f(\boldsymbol{\mathsf{x}}_{t-1}; \boldsymbol{\Theta}).\)
Modeling counts#
The following works for n-grams for all n. It models probabilities based on counts with a smoothing parameter \(\alpha\). This is needed in case of zero counts, i.e. when contexts are not encountered in the training dataset, the model opts for a uniform distribution. As \(\alpha \to \infty\), the output probabilities become more uniform for any input.
class CountingModel:
def __init__(self, alpha=0.01):
"""Sequence model that uses observed n-grams to estimate next char proba."""
self.P = None # cond. prob
self.N = None # counts
self.alpha = alpha # smoothing zero counts
def __call__(self, x: torch.tensor) -> torch.tensor:
return torch.tensor(self.P[tuple(x)])[None, :]
def fit(self, dataset: CharDataset):
n = dataset.get_vocab_size()
self.N = torch.zeros([n + 1] * (dataset.block_size + 1), dtype=torch.int32)
for x, y in dataset:
self.N[tuple(x)][y] += 1
self.P = (self.N + self.alpha)/ (self.N + self.alpha).sum(dim=-1, keepdim=True)
Training the model on input and target sequences:
bigram_model = CountingModel()
bigram_model.fit(bigram_train)
Computing the NLL of the bigram model:
import torch.nn.functional as F
@torch.inference_mode()
def evaluate_model(model, dataset, logits=False):
# Iterate over dataset one-by-one. Slow for large datasets.
loss = 0.0
n = 0
for x, y in dataset:
out = model(x)
p = F.softmax(out, dim=1) if logits else out
loss += -torch.log(p[0][y])
n += 1
if n < 12:
print(f"p({dataset.itos[y.item()]}|{dataset.decode(x)})={p[0][y]:.4f} nll={-torch.log(p[0][y]):.4f}")
print("...")
print(f"nll = {loss / n:.4f} (overall)")
evaluate_model(bigram_model, bigram_valid)
p(b|.)=0.0990 nll=2.3127
p(e|b)=0.2295 nll=1.4721
p(l|e)=0.1366 nll=1.9906
p(t|l)=0.0099 nll=4.6130
p(r|t)=0.0603 nll=2.8079
p(a|r)=0.1783 nll=1.7243
p(m|a)=0.0383 nll=3.2633
p(o|m)=0.1700 nll=1.7722
p(.|o)=0.2505 nll=1.3843
p(v|.)=0.0268 nll=3.6206
p(i|v)=0.2618 nll=1.3401
...
nll = 2.5103 (overall)
Increasing the context size:
trigram_model = CountingModel()
trigram_model.fit(trigram_train)
evaluate_model(trigram_model, trigram_valid)
p(b|..)=0.0990 nll=2.3127
p(e|.b)=0.2641 nll=1.3315
p(l|be)=0.1726 nll=1.7570
p(t|el)=0.0083 nll=4.7881
p(r|lt)=0.0985 nll=2.3175
p(a|tr)=0.3272 nll=1.1171
p(m|ra)=0.0423 nll=3.1623
p(o|am)=0.1224 nll=2.1008
p(.|mo)=0.0592 nll=2.8274
p(v|..)=0.0268 nll=3.6206
p(i|.v)=0.4618 nll=0.7727
...
nll = 2.3533 (overall)
Remark. A model that assigns a probability of 1.0 for each next actual character has a perfect NLL of exactly 0.0. Here our count models get penalized for n-grams which occur rarely on the training dataset. Note that a random prediction is given by:
np.log(NUM_CHARS + 1) # baseline
3.367295829986474
Neural bigram model#
To model bigrams, we consider a neural network with a single layer with a weight tensor \(\boldsymbol{\mathsf W}\) of size (28, 28) that corresponds to the count matrix above. The relevant row of weights is picked out by computing \(\boldsymbol{\mathsf w}_a = \boldsymbol{\mathsf x}_a \boldsymbol{\mathsf W}\) where \(\boldsymbol{\mathsf x}_a\) is the one-hot encoding of the input character \(a.\) Then, we apply softmax to \(\boldsymbol{\mathsf w}_a\) which is a common technique for converting real-valued vectors to probabilities.
The model essentially is initialized with uniform conditional probabilities. The weights are then fine-tuned using SGD such that the probabilities of observed next characters are maximized (i.e. NLL is minimized). This model internally uses one-hot vectors to represent characters:
import torch.nn.functional as F
from torch.utils.data import DataLoader
bigram_dl = DataLoader(bigram_train, batch_size=4, shuffle=False)
x, y = next(iter(bigram_dl))
xenc = F.one_hot(x, num_classes=28).float() # convert to float
plt.imshow(xenc.view(4, -1)[:5, :]); # 0, 8, 2, 19

The model is implemented as follows:
class NNBigramModel:
def __init__(self, alpha=0.01, seed=2147483647):
self.g = torch.Generator().manual_seed(seed)
self.W = torch.randn((NUM_CHARS + 1, NUM_CHARS + 1), generator=self.g, requires_grad=True)
self.alpha = alpha
def __call__(self, x):
"""Returns p(· | x) over characters."""
xenc = F.one_hot(x, num_classes=NUM_CHARS + 1).float()
logits = xenc.view(-1, NUM_CHARS + 1) @ self.W
counts = logits.exp()
probs = (counts + self.alpha) / (counts + self.alpha).sum(1, keepdim=True)
return probs
def zero_grad(self):
self.W.grad = None
Here weights with values in (-inf, +inf) can be interpreted as log-counts of bigrams that start on the row index. This is interesting because growth in the negative direction is different from growth in the positive direction. Applying .exp() we get units of count with values in (0, +inf). These values are normalized to get an output vector with values in (0, 1) which we interpret as a probability distribution. Training the network will make these interpretations valid.

Fig. 47 Schematic diagram of the bigram neural net. Computing the probability assigned by the model on b given a which is represented here as one-hot vector. Note that this is also the backward dependence for a bigram ab encountered during training with the NLL loss.#
Remark. This is a pretty weak model (essentially learning a lookup table). A more complex model reflects a different prior regarding the character dependencies. For example, considering long range dependencies such that the generating names have lengths that follow the distribution of names in the dataset.
Model training#
This should converge to a similar loss value as the bigram counting model (same capacity):
from tqdm.notebook import tqdm
model = NNBigramModel()
bigram_train_loader = DataLoader(bigram_train, batch_size=256, shuffle=True)
bigram_valid_loader = DataLoader(bigram_valid, batch_size=256, shuffle=True)
losses = []
num_steps = 500
for k in tqdm(range(num_steps)):
x, y = next(iter(bigram_train_loader))
probs = model(x)
loss = -probs[torch.arange(len(y)), y].log().mean() # next char nll
model.zero_grad()
loss.backward()
model.W.data -= 10.0 * model.W.grad
# logging
losses.append(loss.item())
if k % int(0.10 * num_steps) == 0 or k == num_steps - 1:
print(f"[{k+1:>03d}/{num_steps}] loss={loss:.4f}")
[001/500] loss=3.7296
[051/500] loss=2.6983
[101/500] loss=2.6277
[151/500] loss=2.5345
[201/500] loss=2.5861
[251/500] loss=2.6743
[301/500] loss=2.5197
[351/500] loss=2.6159
[401/500] loss=2.5778
[451/500] loss=2.4012
[500/500] loss=2.6006
evaluate_model(model, bigram_valid)
p(b|.)=0.1112 nll=2.1961
p(e|b)=0.2486 nll=1.3918
p(l|e)=0.1260 nll=2.0713
p(t|l)=0.0083 nll=4.7942
p(r|t)=0.0495 nll=3.0057
p(a|r)=0.1298 nll=2.0421
p(m|a)=0.0423 nll=3.1629
p(o|m)=0.1735 nll=1.7517
p(.|o)=0.2475 nll=1.3965
p(v|.)=0.0241 nll=3.7258
p(i|v)=0.2418 nll=1.4198
...
nll = 2.5381 (overall)
Show code cell source
plt.figure(figsize=(5, 3))
plt.plot(losses)
plt.ylabel('loss')
plt.xlabel('step');

Sampling#
Generating names and its associated NLL:
def name_loss(name, model, dataset):
nll = 0.0
context = "." * dataset.block_size
for c in name + ".":
p = model(dataset.encode(context))[0, dataset.stoi[c]]
nll += -math.log(p)
context = context[1:] + c
return nll / (len(name) + 1)
sample = generate_names(model, bigram_train, sample_size=12, seed=0)
name_losses = {n: name_loss(n, model, bigram_train) for n in sample}
for n in sorted(sample, key=lambda n: name_losses[n]):
print(f"{n:<50} {name_losses[n]:.3f}")
s 1.923
meti 2.192
belaririmorer_rer 2.323
adenabide 2.389
anaño 2.405
galabarzamigereñernes 2.480
sansibanlino 2.574
osahisestr 2.733
gelijasaciceicoxabi 2.827
ailcaui 2.828
itan_mbamcfeiesagulo 2.917
efroci 3.187
Recall that instead of maximizing names, we are maximizing next character likelihood. Hence, we can get names with low NLL (relative to the random baseline) even if these seem unlikely to occur naturally. Note that this is exactly the strength of generative models. Consequently, it should be rare that a generated name is in the training dataset:
print(r"Generated names found in train dataset:")
sample_size = 1000
print(f"{100 * sum([n in names for n in generate_names(model, bigram_train, sample_size=sample_size)]) / sample_size}% (sample_size={sample_size})")
Generated names found in train dataset:
4.5% (sample_size=1000)
From the conditional distributions, it looks like the neural net recovered the count matrix!
Show code cell source
counts = model.W.exp()
P2_nn = (counts / counts.sum(dim=1, keepdim=True)).data
fig, ax = plt.subplots(1, 2)
fig.tight_layout()
ax[0].imshow(P2)
ax[0].set_title("count")
ax[1].imshow(P2_nn)
ax[1].set_title("NN");

Remark. That one yellow dot is for “qu”. ☺
Character embeddings#
In this section, we implement a language model that uses learns character embeddings. This approach leads to better generalization due to the added complexity of having character encodings as learnable vectors, in contrast to our earlier approach of learning a large lookup table for each sequence of characters as context.
Network architecture#
The architecture [BDVJ03] is shown in the following figure.

Fig. 48 Schematic diagram of our MLP neural net with embedding and block size of 3. Shown here is the input string "ner" passed to the embedding layer. Note that the embeddings are concatenated in the correct order. The resulting concatenation of embeddings are passed to the two-layer MLP with logits.#
The first component of the network is an embedding matrix, where each row corresponds to an embedding vector. Then, the embedding vectors are concatenated in the correct order and passed to the two-layer MLP to get the logits after a dense operation.
import torch.nn as nn
from torchinfo import summary
class MLP(nn.Module):
def __init__(self,
emb_size: int,
width: int,
block_size: int,
vocab_size: int = NUM_CHARS + 1):
super().__init__()
self.C = nn.Embedding(vocab_size, emb_size)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(block_size * emb_size, width)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(width, vocab_size)
def forward(self, x):
x = self.flatten(self.C(x))
h = self.relu(self.fc1(x))
z = self.fc2(h)
return z
model = MLP(emb_size=10, width=64, block_size=3)
summary(model, input_data=torch.tensor([[0, 0, 0] for _ in range(32)]))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MLP [32, 29] --
├─Embedding: 1-1 [32, 3, 10] 290
├─Flatten: 1-2 [32, 30] --
├─Linear: 1-3 [32, 64] 1,984
├─ReLU: 1-4 [32, 64] --
├─Linear: 1-5 [32, 29] 1,885
==========================================================================================
Total params: 4,159
Trainable params: 4,159
Non-trainable params: 0
Total mult-adds (M): 0.13
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.03
Params size (MB): 0.02
Estimated Total Size (MB): 0.05
==========================================================================================
Remark. In case we want to regularize the model, weight decay should only be applied to the weights (i.e. not to biases, embeddings, or the like), so that network expressivity is not too strongly limited. See this post on the PyTorch forums on how to do this.
Backpropagation. Refer to this section for backpropagating across a linear operation. Here we will be mostly interested with backpropagating through the embedding layer. Observe that the gradient of \(\bar{\boldsymbol{{\mathsf{x}}}}\) is just the gradient of \(\bar{\boldsymbol{{\mathsf{x}}}}_{\text{cat}}\) reshaped. The embedding operation can be written as \(\bar{\boldsymbol{{\mathsf{x}}}}_{btj} = \mathsf{C}_{\boldsymbol{\mathsf{x}}_{bt}j}.\) Hence:
This looks more complicated than it actually is. The last formula is essentially an instruction on where to add the gradients of \(\bar{\boldsymbol{{\mathsf{x}}}}\) for entries that are pulled out of \(\mathsf{C}.\) However, note that we are summing also over the batch index since these instances share the same embedding weights.
x = torch.stack(xs[:4], dim=0)
C = torch.randn(NUM_CHARS + 1, 10, requires_grad=True)
W = torch.randn(30, 4, requires_grad=True)
b = torch.randn(4, requires_grad=True)
x̄ = C[x]
x̄_cat = x̄.view(x̄.shape[0], -1)
y = x̄_cat @ W + b
for u in [x̄, x̄_cat, y]:
u.retain_grad()
loss = (y ** 2).sum(dim=1).mean()
loss.backward()
It follows that the gradient of the embedding matrix is:
δ = F.one_hot(x, num_classes=NUM_CHARS + 1).view(-1, NUM_CHARS + 1).float()
dC = δ.T @ x̄.grad.view(-1, 10)
# Checking with autograd
print("maxdiff:", (dC - C.grad).abs().max().item(), "\texact:", torch.all(dC == C.grad).item())
maxdiff: 0.0 exact: True
# Three input sequences in a batch (B = 4)
δ = F.one_hot(x, num_classes=NUM_CHARS + 1).view(-1, NUM_CHARS + 1).float().T
δ[:, 3: 6] += 1 # add shade
δ[:, 6: 9] += 2
δ[:, 9:12] += 3
fig, ax = plt.subplots(1, 2)
ax[0].imshow(δ.tolist(), interpolation='nearest', cmap='gray')
ax[0].set_xlabel('$(b, t)$')
ax[0].set_ylabel('$i$ (characters)')
ax[1].imshow(x̄.grad.view(-1, 10), interpolation='nearest')
ax[1].set_ylabel('$(b, t)$')
ax[1].set_xlabel('$j$ (embedding)');

Figure. Kronecker delta tensor (left) and gradient tensor (right) from the above equation are visualized. The tensor \(\boldsymbol{\delta}_{i\boldsymbol{\mathsf{x}}_{bt}}\) indicates all indices \((b, t)\) where the i-th character occurs. All embedding vector gradients \(\frac{\partial{\mathcal{L}}}{\partial\bar{\boldsymbol{{\mathsf{x}}}}_{bt:}}\) for the \(i\)th character are then added over all time steps to get \(\frac{\partial{\mathcal{L}}}{\partial \mathsf{C}_{i:}}.\) Note that time-dependence can be seen here since the gradients of the embedding for the same character varies over different time steps.
Model training#
We will use our training engine defined on a previous notebook:
Show code cell source
from tqdm.notebook import tqdm
from contextlib import contextmanager
from torch.utils.data import DataLoader
DEVICE = "mps"
@contextmanager
def eval_context(model):
"""Temporarily set to eval mode inside context."""
state = model.training
model.eval()
try:
yield
finally:
model.train(state)
class Trainer:
def __init__(self,
model, optim, loss_fn, scheduler=None, callbacks=[],
device=DEVICE, verbose=True
):
self.model = model
self.optim = optim
self.device = device
self.loss_fn = loss_fn
self.train_log = {'loss': [], 'loss_avg': []}
self.valid_log = {'loss': []}
self.verbose = verbose
self.scheduler = scheduler
self.callbacks = callbacks
def __call__(self, x):
return self.model(x.to(self.device))
def forward(self, batch):
x, y = batch
x = x.to(self.device)
y = y.to(self.device)
return self.model(x), y
def train_step(self, batch):
preds, y = self.forward(batch)
loss = self.loss_fn(preds, y)
loss.backward()
self.optim.step()
self.optim.zero_grad()
return {'loss': loss}
@torch.inference_mode()
def valid_step(self, batch):
preds, y = self.forward(batch)
loss = self.loss_fn(preds, y, reduction='sum')
return {'loss': loss}
def run(self, epochs, train_loader, valid_loader, window_size=None):
for e in tqdm(range(epochs)):
for i, batch in enumerate(train_loader):
# optim and lr step
output = self.train_step(batch)
if self.scheduler:
self.scheduler.step()
# step callbacks
for callback in self.callbacks:
callback()
# logs @ train step
steps_per_epoch = len(train_loader)
w = int(0.05 * steps_per_epoch) if not window_size else window_size
self.train_log['loss'].append(output['loss'].item())
self.train_log['loss_avg'].append(np.mean(self.train_log['loss'][-w:]))
# logs @ epoch
output = self.evaluate(valid_loader)
self.valid_log['loss'].append(output['loss'])
if self.verbose:
print(f"[Epoch: {e+1:>0{int(len(str(epochs)))}d}/{epochs}] loss: {self.train_log['loss_avg'][-1]:.4f} val_loss: {self.valid_log['loss'][-1]:.4f}")
def evaluate(self, data_loader):
with eval_context(self.model):
valid_loss = 0.0
for batch in data_loader:
output = self.valid_step(batch)
valid_loss += output['loss'].item()
return {'loss': valid_loss / len(data_loader.dataset)}
@torch.inference_mode()
def predict(self, x: torch.Tensor):
with eval_context(self.model):
return self(x)
@torch.inference_mode()
def batch_predict(self, input_loader: DataLoader):
with eval_context(self.model):
preds = [self(x) for x in input_loader]
preds = torch.cat(preds, dim=0)
return preds
from torch.optim.lr_scheduler import OneCycleLR
train_dataset = build_dataset(names_train, block_size=3)
valid_dataset = build_dataset(names_valid, block_size=3)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=128, shuffle=False)
epochs = 15
model = MLP(emb_size=3, width=64, block_size=3).to(DEVICE)
loss_fn = F.cross_entropy
optim = torch.optim.AdamW(model.parameters(), lr=0.001)
scheduler = OneCycleLR(optim, max_lr=0.01, steps_per_epoch=len(train_loader), epochs=epochs)
trainer = Trainer(model, optim, loss_fn, scheduler, device=DEVICE)
trainer.run(epochs=epochs, train_loader=train_loader, valid_loader=valid_loader)
[Epoch: 01/15] loss: 2.5935 val_loss: 2.5791
[Epoch: 02/15] loss: 2.4473 val_loss: 2.4507
[Epoch: 03/15] loss: 2.3881 val_loss: 2.4172
[Epoch: 04/15] loss: 2.3885 val_loss: 2.4021
[Epoch: 05/15] loss: 2.4309 val_loss: 2.3906
[Epoch: 06/15] loss: 2.3695 val_loss: 2.3761
[Epoch: 07/15] loss: 2.3559 val_loss: 2.3636
[Epoch: 08/15] loss: 2.3643 val_loss: 2.3585
[Epoch: 09/15] loss: 2.3289 val_loss: 2.3504
[Epoch: 10/15] loss: 2.3701 val_loss: 2.3424
[Epoch: 11/15] loss: 2.3595 val_loss: 2.3300
[Epoch: 12/15] loss: 2.2960 val_loss: 2.3278
[Epoch: 13/15] loss: 2.2970 val_loss: 2.3212
[Epoch: 14/15] loss: 2.3245 val_loss: 2.3194
[Epoch: 15/15] loss: 2.2952 val_loss: 2.3189
Best performance so far.
Show code cell source
from matplotlib.ticker import StrMethodFormatter
num_epochs = len(trainer.valid_log["loss"])
num_steps_per_epoch = len(trainer.train_log["loss"]) // num_epochs
plt.figure(figsize=(6, 4))
plt.gca().yaxis.set_major_formatter(StrMethodFormatter("{x:,.2f}")) # 2 decimal places
plt.plot(np.array(trainer.train_log["loss"]), alpha=0.6, color="C0")
plt.ylabel("loss")
plt.xlabel("steps")
plt.plot(np.array(trainer.train_log["loss_avg"]), color="C0", label="train")
plt.plot(list(range(num_steps_per_epoch, (num_epochs + 1) * num_steps_per_epoch, num_steps_per_epoch)), trainer.valid_log["loss"], label="valid", color="C1")
plt.grid(linestyle="dotted")
plt.legend();

Generated names are looking better:
for n in generate_names(lambda x: F.softmax(model.to("cpu")(x), dim=1), train_dataset, sample_size=12):
print(n)
bassi
mados
min
tarmin
bolnia
pille
lana
reuch
vidi
mures
maguel
paro
Looking at the trained character embeddings:
Show code cell source
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Scatter plot the embeddings; annotate
embeddings = model.C.weight.data.detach().cpu().numpy()
ax.scatter(embeddings[:,0], embeddings[:,1], embeddings[:,2])
for i, char in enumerate(train_dataset.chars):
ax.text(embeddings[i,0], embeddings[i, 1], embeddings[i, 2], char)
ax.set_title('Trained embeddings')
plt.show()

Figure. Observe that there are vectors that are isolated from other vectors. On the other hand, characters being tightly clustered indicates that the network is not able to understand the subtle differences between them.
This indicates that embedding dimension may be a bottleneck and therefore can be increased to improve performance. Indeed, performance improved after increasing embedding dimension from 2 to 3 with other variables fixed.
Appendix: Causal convolutions#
One problem with our previous network is that sequential information from the inputs are mixed or squashed too fast (i.e. in one layer). We can make this network deeper by adding dense layers, but it still does not solve this problem. In this section, we implement a convolutional neural network architecture similar to WaveNet [vdODZ+16]. This allows the character embeddings to be fused slowly.
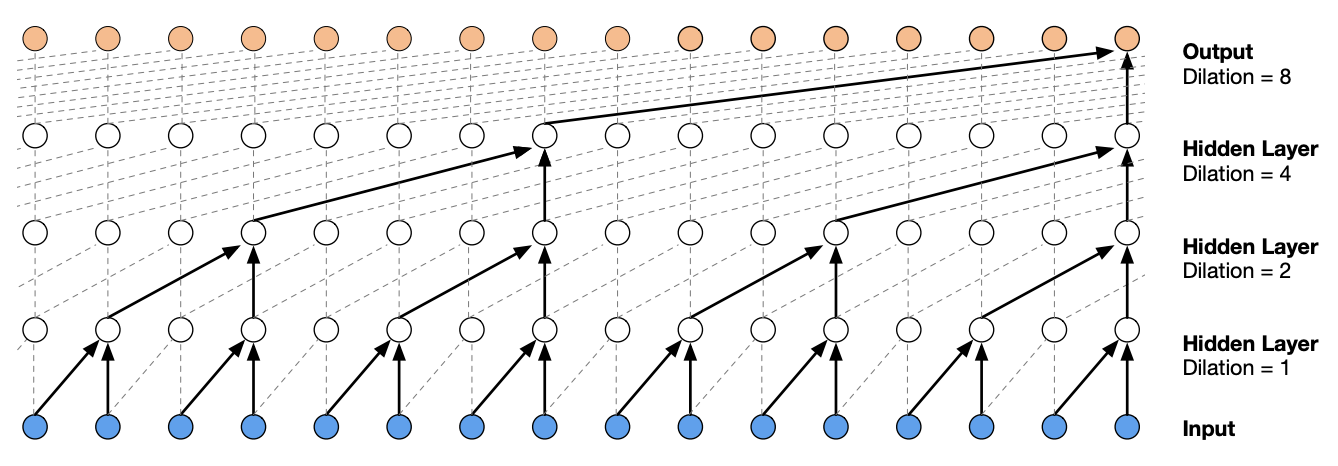
Fig. 49 [vdODZ+16] Tree-like structure formed by a stack of dilated causal convolutional layers. The term causal is used since the network is constrained so that an output node at position t can only depend on input nodes at position t-k:t.#
The structure of the network allows us to use a larger block size. Previously, increasing block size by 1 means that the network width increases equal to the embedding dimension. For this network, the width is fixed but we have to increase depth.
train_dataset = build_dataset(names_train, block_size=8)
valid_dataset = build_dataset(names_valid, block_size=8)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=128)
for x, y in zip(train_dataset.xs, train_dataset.ys):
print("".join(x), "-->", y)
if y == ".":
break
........ --> d
.......d --> u
......du --> r
.....dur --> a
....dura --> n
...duran --> a
..durana --> .
To implement this without using dilated convolutions, we define the following class
so that only two characters are combined at each step. The linear layer is applied to
the last dimension which the following layer expands. Here n corresponds to the number
of characters that are combined at each step.
class FlattenConsecutive(nn.Module):
def __init__(self, n: int):
super().__init__()
self.n = n
def forward(self, x):
B, T, C = x.shape # (batch, char, emb)
x = x.view(B, T // self.n, C * self.n)
return x
To see how this works:
B, T, C = 2, 4, 2
x = torch.rand(B, T, C)
x
tensor([[[0.6472, 0.8232],
[0.6742, 0.3912],
[0.4131, 0.9134],
[0.4836, 0.0824]],
[[0.1545, 0.1227],
[0.5478, 0.8656],
[0.7991, 0.6323],
[0.6666, 0.2632]]])
x.view(B, T // 2, C * 2)
tensor([[[0.6472, 0.8232, 0.6742, 0.3912],
[0.4131, 0.9134, 0.4836, 0.0824]],
[[0.1545, 0.1227, 0.5478, 0.8656],
[0.7991, 0.6323, 0.6666, 0.2632]]])
Information from characters can flow better through the network due to its heirarchical nature. This allows us to increase embedding size and width, as well as make the network is deeper. Note that we need three layers to combine all characters: 2 x 2 x 2 = 8 (block size). This looks like our previous network. Stride happens in the way character blocks are fed to the layers, so convolutions need not be explicitly used.
emb_size = 24
width = 128
VOCAB_SIZE = NUM_CHARS + 1
wavenet = nn.Sequential(
nn.Embedding(VOCAB_SIZE, emb_size),
FlattenConsecutive(2), nn.Linear(emb_size * 2, width), nn.ReLU(),
FlattenConsecutive(2), nn.Linear( width * 2, width), nn.ReLU(),
FlattenConsecutive(2), nn.Linear( width * 2, width), nn.ReLU(),
nn.Linear(width, VOCAB_SIZE), nn.Flatten() # flatten: rank 3 -> rank 2
)
epochs = 5
wavenet = wavenet.to(DEVICE)
loss_fn = F.cross_entropy
optim = torch.optim.AdamW(wavenet.parameters(), lr=0.001)
scheduler = OneCycleLR(optim, max_lr=0.01, steps_per_epoch=len(train_loader), epochs=epochs)
trainer = Trainer(wavenet, optim, loss_fn, scheduler, device=DEVICE)
trainer.run(epochs=epochs, train_loader=train_loader, valid_loader=valid_loader)
[Epoch: 1/5] loss: 2.3383 val_loss: 2.3435
[Epoch: 2/5] loss: 2.2948 val_loss: 2.2925
[Epoch: 3/5] loss: 2.2069 val_loss: 2.2200
[Epoch: 4/5] loss: 2.1020 val_loss: 2.1675
[Epoch: 5/5] loss: 2.0544 val_loss: 2.1523
Remark. Finally broke through 2.3 loss!
Show code cell source
from matplotlib.ticker import StrMethodFormatter
num_epochs = len(trainer.valid_log["loss"])
num_steps_per_epoch = len(trainer.train_log["loss"]) // num_epochs
a = np.array(trainer.train_log["loss_avg"])[0] + 0.1
b = np.array(trainer.train_log["loss_avg"])[-1] - 0.1
plt.figure(figsize=(6, 4))
plt.gca().yaxis.set_major_formatter(StrMethodFormatter("{x:,.2f}")) # 2 decimal places
plt.plot(np.array(trainer.train_log["loss"]), alpha=0.6, color="C0")
plt.ylabel("loss")
plt.xlabel("steps")
plt.plot(np.array(trainer.train_log["loss_avg"]), color="C0", label="train")
plt.plot(list(range(num_steps_per_epoch, (num_epochs + 1) * num_steps_per_epoch, num_steps_per_epoch)), trainer.valid_log["loss"], label="valid", color="C1")
plt.grid(linestyle="dotted")
plt.legend();

■