Introduction to NNs#



Readings: [CS182-lec1] [CS182-lec2] [CS182-lec3] [CS4780-lec12] [RSW+17]
Introduction#
Deep learning models can be characterized as machine learning models with multiple layers of learned representations. Here a layer refers to any transformation that maps an input to its feature representation. In principle, any function that can be described as a composition of layers is called a neural network. Representations are powerful: in machine translation, sentences are not translated one-to-one between words in two languages, instead an intermediate representation of the common “thought” between the translated sentences is learned by the model. (Fig. 2).
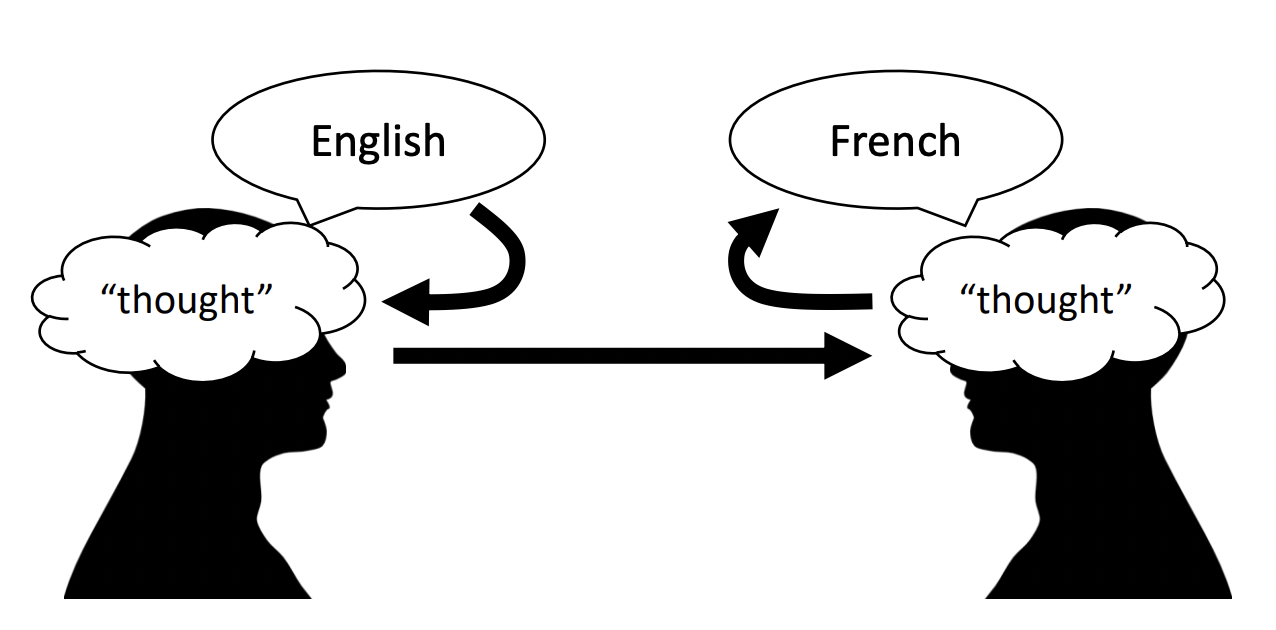
Fig. 2 Thought is a representation.#
The practical success of deep learning can be further attributed to three factors:
complexity: big models, many layers
data: large datasets containing many examples
compute: large compute (GPUs)
Are more layers better? Generally, yes (Fig. 3). Higher level features are more abstract and invariant to noise which makes it easier to learn labels. This requires large models with many layers. And consequently, it requires large datasets with many examples of all different scenarios. This is necessary for the complexity of distributions that it tries to learn. Both these requirements necessitate large compute (Fig. 4).
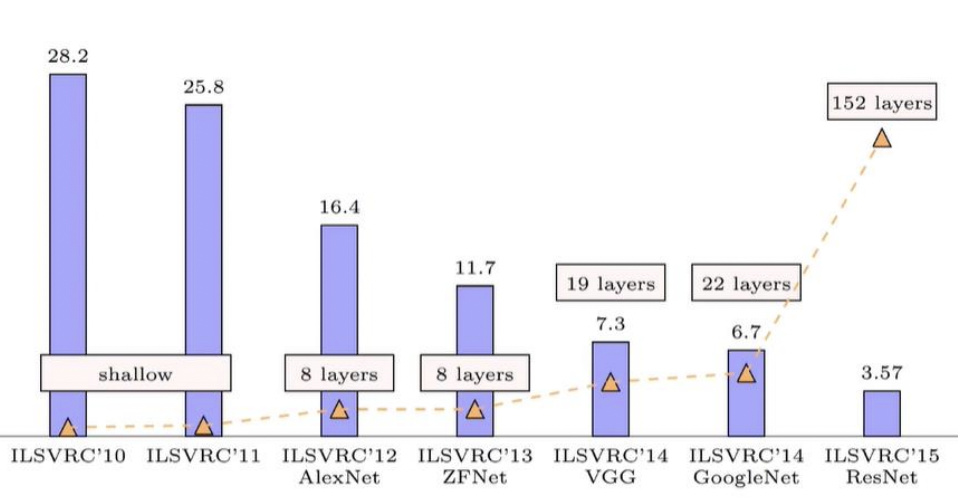
Fig. 3 Progress in top-5 error in the ImageNet competition.#
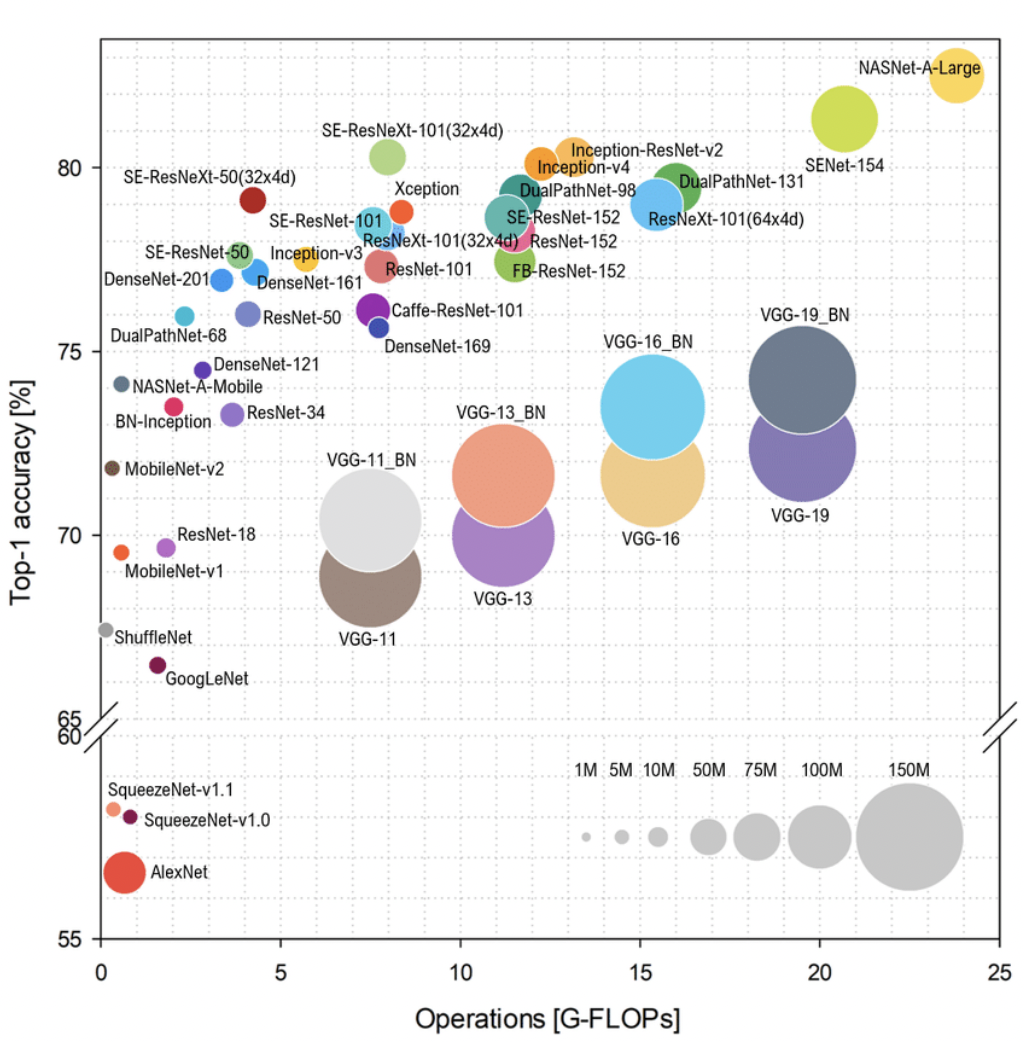
Fig. 4 ResNets are in the middle of the graph. GFlops are a good metric since a network can have large compute with small number of parameters (e.g. convolutions).#
DL is resource intensive, so it is natural to ask whether it is a good idea. The tradeoff is that DL models have very high capacity and are immediately scalable that as we add more layers, more data, and more compute, the models just get better and better. Moreover, DL models acquire representations end-to-end purely from the data without requiring manual engineering of features or representations. Such representations are better tailored to the current task and minimizes inductive bias. Indeed, DL has been able to beat several human benchmark on specific tasks tasks [MKS+15] [DCLT19].
Remark. Model capacity refers to how many different functions a particular model class can represent. Roughly if model capacity is sufficiently large, its function space contains the true function that underlies the task. Model capacity can be controlled by parameter count in certain architectures. Inductive bias refers to built-in knowledge or biases in a model designed to help it learn. All such knowledge is “bias” in the sense that it makes some solutions more likely and some less likely. Scaling is the ability for an algorithm to work better as data and model capacity is increased.
Fully-connected NNs / MLPs#
Fully-connected networks consist of a sequence of dense layers followed by an activation function. A dense layer consist of neurons which compute \(\mathsf{y}_k = \varphi(\boldsymbol{\mathsf{x}} \cdot \boldsymbol{\mathsf{w}}_k + b_k)\) for \(k = 1, \ldots, H\) where the activation \(\varphi\colon \mathbb{R} \to \mathbb{R}\) is a nonlinear function. The number of neurons \(H\) is called the width of the layer. The number of layers in a network is called its depth. Fully-connected networks are also historically known as multilayer perceptrons (MLPs).
This can be written in terms of matrix multiplication: \(\boldsymbol{\mathsf{X}}^1 = \varphi\left(\boldsymbol{\mathsf{X}}^0\,\boldsymbol{\mathsf{W}} + \boldsymbol{\mathsf{b}}\right)\) where \(B\) data points in \(\mathbb{R}^d\) are stacked so that the input \(\boldsymbol{\mathsf{X}}^0\) has shape \((B, d)\) allowing the network to process data in parallel. The layer output is then passed as input to the next layer.
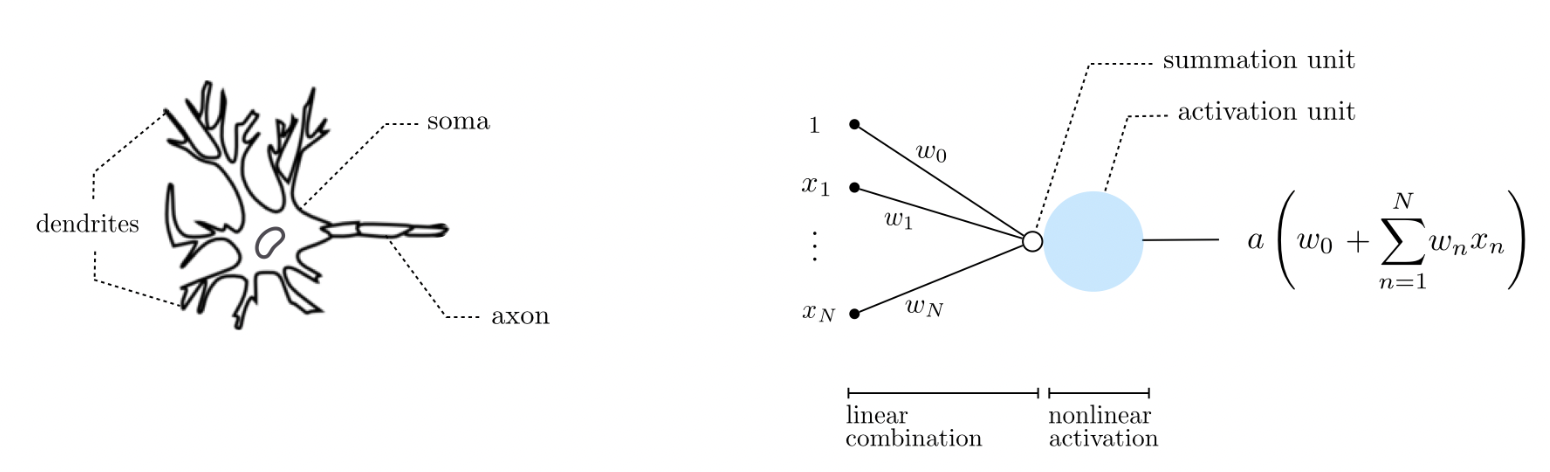
Fig. 5 An artificial neuron is a simplistic mathematical model for the biological neuron. Biological neurons are believed to remain inactive until the net input to the cell body (soma) reaches a certain threshold, at which point the neuron gets activated and fires an electro-chemical signal. Source#
It turns out that fully-connected neural networks can approximate any continuous function \(f\) from a closed and bounded set \(K \subset \mathbb{R}^d\) to \(\mathbb{R}^m.\) This is a reasonable assumption about a ground truth function which we assume to exist. The following approximates a one-dimensional curve using a neural network with ReLU activation: \(z \mapsto \max(0, z)\) for \(z \in \mathbb{R}.\)
import torch
# Ground truth
x = torch.linspace(-2*torch.pi, 2*torch.pi, 1000)
y = torch.sin(x) + 0.3 * x
# Get (sorted) sample
B = torch.randint(0, 1000, size=(24,))
B = torch.sort(B)[0]
xs = x[B]
ys = y[B]
# ReLU approximation
z = torch.zeros(1000,)
for i in range(len(xs) - 1):
if torch.isclose(xs[i + 1], xs[i]):
m = torch.tensor(0.0)
else:
M = (ys[i+1] - ys[i]) / (xs[i+1] - xs[i])
s, m = torch.sign(M), torch.abs(M)
z += s * (torch.relu(m * (x - xs[i])) - torch.relu(m * (x - xs[i+1])))
z += ys[0]
Note this only works (consistent with the theorem) for target function with domain [a, b].
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# Plotting
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
ax[0].scatter(xs, ys, facecolor='none', s=12, edgecolor='k', zorder=3, label='data')
ax[0].plot(x, y, color="C1", label='f')
ax[0].set_xlabel('x')
ax[0].set_ylabel('y')
ax[0].legend();
ax[1].scatter(xs, ys, facecolor='none', s=12, edgecolor='k', zorder=4, label='data')
ax[1].plot(x, z, color="C0", label=f'relu approx. (B={len(B)})', zorder=3)
ax[1].plot(x, y, color="C1")
ax[1].set_xlabel('x')
ax[1].set_ylabel('y')
ax[1].legend();

This works by constructing ___/‾‾‾ and ‾‾‾\___ functions similar to step functions but with slope in between adjacent points. The step functions increment each other starting with the constant function ys[0]. Note this correctly ends with a constant function ys[-1].
Linear classification#
Neural networks learn to classify by finding separating hyperplanes for vectors obtained after a sequence of transformations on the input. The intermediate layer outputs are what we call representations. The distance of a data point to each hyperplane are interpreted as unnormalized class scores and are called logits. Note that instead of labels, we want to predict probabilities since these are differentiable. We can apply any increasing positive function \(f\) to class scores to convert it to a probability vector:
A natural choice for \(f\) is the exponential which maps \(\mathbb R\) to \(\mathbb R^+\) one-to-one with \(e^{-\infty} = 0.\) The resulting function is called the softmax function:
For binary classification, we only have to compute the probability of one class since \(p_0 + p_1 = 1.\) In this case, we recover the sigmoid function: \(p_1 = {1}/\left(1 + e^{-(s_1 - s_0)}\right)\) for the probability of the positive label. Notice that logistic regression can be implemented as a single layer neural network with \(s_k = \boldsymbol{\mathsf{w}}_k \cdot \boldsymbol{\mathsf{x}} + b_k\) so that we get fused weights and biases:
i.e. one separating hyperplane.
Remark. Softmax can be stabilized to have demoninator at least 1 by dividing the numerator and denominator with \(e^{s_*}\) where \(s^* = \max_j s_j.\) This gives us \(\text{Softmax}(\boldsymbol{\mathsf{s}})_j = {e^{s_j - s_*}}/({\sum_k e^{s_k - s_*}})\) commonly used in deep learning frameworks.
s = np.linspace(-10, 10, 300)
p = 1 / (1 + np.exp(-s))
p_inv = lambda p: np.log(p / (1 - p))
threshold = 0.15
s_lo = p_inv(threshold)
s_hi = p_inv(1 - threshold)
s0 = [-8.0, -7.8, -6.5, -5.0, -2.5, -1.25, 0.3, -7.6] # y = 0
s1 = [-2.2, 0.0, 6.0, 1.3, 5.0, 7.5, 7.6, 8.3] # y = 1
Show code cell source
plt.figure(figsize=(10, 5))
plt.title(r"logistic regression ($\tau = 0.15$)")
plt.plot(s, p, label="$p(y=1 \mid {\mathbf{x}}) = 1 / (1 + e^{-s})$", color="C1")
for i in range(len(s0)):
plt.scatter(s0[i], 0.0, color="C0", zorder=3, edgecolor='k')
plt.scatter(s1[i], 0.0, color="C1", zorder=3, edgecolor='k')
plt.axvspan(-10.0, s_lo, -2.0, 2.0, color='C0', label=r"$\hat{y} = 0$", alpha=0.3)
plt.axvspan( s_hi, 10.0, -2.0, 2.0, color='C1', label=r"$\hat{y} = 1$", alpha=0.3)
plt.axvspan( s_lo, s_hi, -2.0, 2.0, color='lightgray', label="???")
plt.xlabel("$s$")
plt.ylabel("$p$")
plt.legend()
plt.ylim(-0.1, 1.1)
plt.grid(linestyle="dotted");

Note that the sigmoid assigns \(p =\frac{1}{2}\) at the hyperplane where \(s = 0.\) It scales symmetrically with respect to the distance of the data points from the decision boundary. This is nice otherwise the prediction will not be invariant with respect to relabeling. For the general case of multiclass classification, we will have class scores \(s_k = \boldsymbol{\mathsf{w}}_k \cdot \boldsymbol{\mathsf{x}}\) and the softmax will act like a voting function. See this video for deeper reasons on using the softmax function.
# grid of points
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
X, Y = np.meshgrid(x, y)
# parameters
w = [1, 1]
b = 0
def sigmoid_neuron(x, y):
z = w[0] * x + w[1] * y + b
return 1 / (1 + np.exp(-z))
def relu_neuron(x, y):
z = w[0] * x + w[1] * y + b
return np.maximum(0, z)
The sigmoid unit assigns a gradient along the normal of the hyperplane defined by \(\boldsymbol{\mathsf{w}}\) and \(b\) in the input space \(\mathbb{R}^2\). This effectively reduces the input space to one dimension along the direction of \({\boldsymbol{\mathsf{w}}} = [1, 1].\) Here \(H\) is the linear decision boundary defined by points \(\boldsymbol{\mathsf{x}}\) such that \(\boldsymbol{\mathsf{x}} \cdot \boldsymbol{\mathsf{w}} + b = 0.\) ReLU unit has sharp cutoff at zero.
Show code cell source
from matplotlib.colors import LinearSegmentedColormap
colors = ["C0", "C1"]
n_bins = 100
cm = LinearSegmentedColormap.from_list(name="", colors=colors, N=n_bins)
def plot_grid(ax, X, Y, Z):
p1 = (-0.45, -0.45)
p2 = (1, 1)
ax.annotate(f'$\mathsf{{w}}$', xy=p2, xytext=p1, arrowprops=dict(arrowstyle='->'))
ax.plot(x, -x, color='k', linewidth=1, linestyle='dotted', label='H')
im = ax.pcolormesh(X, Y, Z, shading='auto', cmap=cm)
cbar = plt.colorbar(im, ax=ax)
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
ax.legend()
Z0 = sigmoid_neuron(X, Y)
Z1 = relu_neuron(X, Y)
fig, ax = plt.subplots(1, 2, figsize=(11, 4))
plot_grid(ax[0], X, Y, Z0)
plot_grid(ax[1], X, Y, Z1)

This is the immediate representation that gets passed to the next layer. The next layer can then take a weighted combination of these surfaces to construct a complex leveling of the input space. Another way to think about this is that a weight vector \(\boldsymbol{\mathsf{w}}\) corresponds to a learned pattern, so that the projection \(\boldsymbol{\mathsf{x}} \cdot \boldsymbol{\mathsf{w}}\) of the input \(\boldsymbol{\mathsf{x}}\) to \(\boldsymbol{\mathsf{w}}\) corresponds to a scaled similarity. The activation function determines whether this plus the bias \(b\) is enough to activate the unit.
Remark. In general, we learn a weight vector for each class, and there are as many separating hyperplanes as the number of classes. For binary classification with softmax, the weight vectors and biases fuse resulting in one separating plane.
Negative log loss (MLE)#
The machine learning method follows four steps: defining a model, defining a loss function, choosing an optimizer, and running it on large compute (e.g. GPUs). A loss function acts a smooth surrogate to the true objective which may not be amenable to available optimization techniques. Hence, we can think of loss functions as a measure of model quality. The choice of loss function determines what the model parameters will optimize towards.
Here we derive a loss function based on maximum likelihood estimation (MLE). This results in finding optimal parameters such that the dataset is more probable. Consider a parametric model of the target \(p_{\boldsymbol{\Theta}}(y \mid \boldsymbol{\mathsf{x}}).\) The likelihood of the iid sample \(\mathcal{D} = \{(\boldsymbol{\mathsf{x}}_i, y_i)\}_{i=1}^N\) can be defined as
This can be thought of as the probability assigned by the parametric model on the sample. The iid assumption is important. It also means that the model gets to focus on inputs that are more probable since they are better represented in the sample. Probabilities are small numbers in \([0, 1]\) and we are multiplying lots of them, so applying the logarithm which is monotonic and converts the product into a sum is a good idea:
MLE then maximizes the log-likelihood with respect to the parameters \(\boldsymbol{\Theta}.\) The idea is that a good model should make the data more probable. It is common practice in optimization literature to convert this to a minimization problem. The following then becomes our optimization problem:
This allows us to define \(\ell = -\log p_{\boldsymbol{\Theta}}(y \mid \boldsymbol{\mathsf{x}}).\) In general, the loss function can be any nonnegative function whose value approaches zero whenever the prediction of the network the target value. Observe that:
\(p_{\boldsymbol{\Theta}}(y \mid \boldsymbol{\mathsf{x}}) \to 1\) \(\implies\) \(\ell \to 0\)
\(p_{\boldsymbol{\Theta}}(y \mid \boldsymbol{\mathsf{x}}) \to 0\) \(\implies\) \(\ell \to \infty\)
Using an expectation of the loss over the underlying distribution allows the model to focus on errors based on its probability of occuring. For parameters \(\boldsymbol{\Theta},\) we will approximate the true risk which is the expectation of \(\ell\) on the underlying distribution with the empirical risk calculated on the sample \(\mathcal{D}\):
The optimization problem can be written more generally as \(\boldsymbol{\Theta}^* = \underset{\boldsymbol{\Theta}}{\text{argmin}}\, \mathcal{L}_\mathcal{D}(\boldsymbol{\Theta}) \).
Gradient descent#
Now that we have the empirical risk \(\mathcal{L}_\mathcal{D}(\boldsymbol{\Theta})\) (1) as objective, we proceed to the actual optimization algorithm. Given the current parameters \(\boldsymbol{\Theta} \in \mathbb R^M\) of the network, we can imagine the network to be sitting on a point \((\boldsymbol{\Theta}, \mathcal L_{\mathcal{D}}(\boldsymbol{\Theta}))\) on a surface in \(\mathbb R^M \times \mathbb R.\) The surface will generally vary for different samples of the training data. Training is equivalent to finding the minimum of this surface. Gradients arise in deep learning when making the following first-order approximation:
It follows that \(-\nabla_{\boldsymbol{\Theta}}\, \mathcal L_{\mathcal{D}}\) is the direction of steepest descent at the current point \((\boldsymbol{\Theta}, \mathcal L_{\mathcal{D}})\) in the surface. Gradient descent (GD) is defined by the update rule:
where the learning rate \(\eta > 0\) controls the step size. Note that finding good initial weights \(\boldsymbol{\Theta}^0 \in \mathbb{R}^M\) is crucial since networks has lots of internal symmetries and can diverge in the early stages of training. Later on we will see that other optimization algorithms in deep learning practice are just modifications of GD.
def loss(w, X, y):
return ((X @ w - y)**2).mean()
def grad(w, X, y, B=None):
"""Gradient step for the MSE loss function"""
dw = 2*((X @ w - y).reshape(-1, 1) * X).mean(axis=0)
return dw / np.linalg.norm(dw)
def grad_descent(w0, X, y, eta=0.1, steps=10):
"""Return sequence of weights from GD."""
w = np.zeros([steps, 2])
w[0, :] = w0
for j in range(1, steps):
u = w[j-1, :]
w[j, :] = u - eta * grad(u, X, y)
return w
# Generate data
n = 1000
X = np.zeros((n, 2))
X[:, 1] = np.random.uniform(low=-1, high=1, size=n)
X[:, 0] = 1
w_min = np.array([-1, 3])
y = (X @ w_min) + 0.05 * np.random.randn(n) # data: y = -1 + 3x + noise
# Gradient descent
w_init = [-4, -4]
w_step = grad_descent(w_init, X, y, eta=0.5, steps=25)
Show code cell content
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # For 3D plotting
import numpy as np
def plot_surface(ax, data, target, N=50):
x = np.linspace(-5, 5, N)
y = np.linspace(-5, 5, N)
X, Y = np.meshgrid(x, y)
Z = np.zeros_like(X)
for i in range(N):
for j in range(N):
Z[i, j] = loss(np.array([X[i, j], Y[i, j]]), data, target)
ax.plot_surface(X, Y, Z, cmap='Reds')
ax.set_xlabel(f'$w_0$')
ax.set_ylabel(f'$w_1$')
ax.set_title('loss surface')
def plot_contourf(ax, data, target, w_min, w_hist, title="", N=50):
x = np.linspace(-5, 5, N)
y = np.linspace(-5, 5, N)
X, Y = np.meshgrid(x, y)
Z = np.zeros_like(X)
for i in range(N):
for j in range(N):
Z[i, j] = loss(np.array([X[i, j], Y[i, j]]), data, target)
for t in range(1, len(w_hist)):
ax.plot([w_hist[t-1][0], w_hist[t][0]], [w_hist[t-1][1], w_hist[t][1]], color='k')
c = ax.contourf(X, Y, Z, levels=20, cmap='Reds')
ax.scatter(w_min[0], w_min[1], color="red", label='min', zorder=3)
ax.scatter(w_hist[:, 0], w_hist[:, 1], marker='o', s=5, facecolors='k')
ax.set_title(title)
ax.set_xlabel(f'$w_0$')
ax.set_ylabel(f'$w_1$')
plt.colorbar(c, ax=ax)
Show code cell source
# Create a figure and two subplots
fig = plt.figure(figsize=(8, 4))
ax1 = fig.add_subplot(121, projection='3d')
ax2 = fig.add_subplot(122)
# Call the functions with the respective axes
plot_surface(ax1, X, y)
plot_contourf(ax2, X, y, w_min, w_step)
plt.tight_layout()
plt.show()

Figure. Loss surface (left) and gradient descent (right) of a linear function with MSE loss.
Nonlinear decision boundary#
Going back to classification. Let us generate data that is not linearly separable. In this section, we will show that linear classification extends to input data that is not linearly separable. The idea is to apply a sequence of transformations on the input such that the final result becomes linearly separable.
import torch
torch.manual_seed(2)
N = 1500 # sample size
noise = lambda e: torch.randn(N, 2) * e
t = 2 * torch.pi * torch.rand(N, 1)
s = 2 * torch.pi * torch.rand(N, 1)
x0 = torch.cat([0.1 * torch.cos(s), 0.1 * torch.sin(s)], dim=1) + noise(0.05)
x1 = torch.cat([1.0 * torch.cos(t), 1.0 * torch.sin(t)], dim=1) + noise(0.1)
y0 = (torch.ones(N,) * 0).long()
y1 = (torch.ones(N,) * 1).long()
Show code cell source
plt.scatter(x0[:, 0], x0[:, 1], s=2.0, label=0, color="C0")
plt.scatter(x1[:, 0], x1[:, 1], s=2.0, label=1, color="C1")
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.legend()
plt.axis('equal');

Modeling this with a fully-connected neural network with one hidden layer containing units that uses the tanh function as activation: \(\text{tanh}(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}.\) This maps \(\mathbb{R}\) to \([-1, 1]\) symmetrically with \(\text{tanh}(0) = 0\) and \(\text{tanh}(z) \to \pm 1\) as \(z \to \pm\infty.\) Note that tanh is actually just a scaled and translated version of the sigmoid function.
import torch.nn as nn
from torchsummary import summary
model = lambda: nn.Sequential(
nn.Linear(2, 3), nn.Tanh(),
nn.Linear(3, 2)
)
summary(model(), input_size=(2,))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 3] 9
Tanh-2 [-1, 3] 0
Linear-3 [-1, 2] 8
================================================================
Total params: 17
Trainable params: 17
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
----------------------------------------------------------------
Gradient descent on cross-entropy loss (equivalent to NLL):
import torch.nn.functional as F
net = model()
optim = torch.optim.SGD(net.parameters(), lr=0.01)
x = torch.cat([x0, x1])
y = torch.cat([y0, y1])
history = []
for step in range(25000):
s = net(x)
loss = F.cross_entropy(s, y)
loss.backward()
optim.step()
optim.zero_grad()
history.append(loss.item())
plt.figure(figsize=(6, 3))
plt.plot(history)
plt.xlabel("step")
plt.grid(linestyle="dotted", alpha=0.8)
plt.ticklabel_format(axis="x", style="sci", scilimits=(3, 3))
plt.ylabel("loss");

Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# transformations
linear_0 = net[0](x0).detach().numpy()
linear_1 = net[0](x1).detach().numpy()
linear_relu_0 = net[1](net[0](x0)).detach().numpy()
linear_relu_1 = net[1](net[0](x1)).detach().numpy()
# separating hyperplane (see above discussion, i.e. w <- w1 - w0 == logistic reg)
h = 1
w, b = net[2].parameters()
w, b = (w[h] - w[h-1]).detach().numpy(), (b[h] - b[h-1]).detach().numpy()
# plot
fig = plt.figure(figsize=(12, 4))
ax0 = fig.add_subplot(131)
ax1 = fig.add_subplot(132, projection='3d')
ax2 = fig.add_subplot(133, projection='3d')
ax0.grid(alpha=0.8, linestyle="dotted")
ax0.set_axisbelow(True)
ax0.scatter(x0[:, 0], x0[:, 1], s=2.0, label=0, color="C0")
ax0.scatter(x1[:, 0], x1[:, 1], s=2.0, label=1, color="C1")
ax0.set_xlabel("$x_1$")
ax0.set_ylabel("$x_2$")
ax0.set_xlim(-1.5, 1.5)
ax0.set_ylim(-1.5, 1.5)
ax0.set_title("(a) input")
ax0.legend()
ax0.axis('equal')
ax1.scatter(linear_0[:, 0], linear_0[:, 1], linear_0[:, 2], s=3, label=0, color="C0")
ax1.scatter(linear_1[:, 0], linear_1[:, 1], linear_1[:, 2], s=3, label=1, color="C1")
ax1.set_xlabel('$x_1$')
ax1.set_ylabel('$x_2$')
ax1.set_zlabel('$x_3$')
ax1.set_title('(b) linear')
ax2.scatter(linear_relu_0[:, 0], linear_relu_0[:, 1], linear_relu_0[:, 2], s=3, label=0, color="C0")
ax2.scatter(linear_relu_1[:, 0], linear_relu_1[:, 1], linear_relu_1[:, 2], s=3, label=1, color="C1")
ax2.set_xlabel('$x_1$')
ax2.set_ylabel('$x_2$')
ax2.set_zlabel('$x_3$')
ax2.set_title('(c) linear + tanh')
# Generate grid of points
x_min = min(linear_relu_1[:, 0].min(), linear_relu_0[:, 0].min())
x_max = max(linear_relu_1[:, 0].max(), linear_relu_0[:, 0].max())
y_min = min(linear_relu_1[:, 1].min(), linear_relu_0[:, 1].min())
y_max = max(linear_relu_1[:, 1].max(), linear_relu_0[:, 1].max())
a, b, c, d = w[0], w[1], w[2], b
x = np.linspace(x_min, x_max, 50)
y = np.linspace(y_min, y_max, 50)
X, Y = np.meshgrid(x, y)
Z = (-a * X - b * Y - d) / c
# Plot the hyperplane for the positive class
ax2.plot_surface(X, Y, Z, alpha=0.5, color=f"C{h}")
fig.tight_layout();

Checking classification accuracy:
a = (torch.argmax(net(x0), dim=1) == y0).float().mean().item()
b = (torch.argmax(net(x1), dim=1) == y1).float().mean().item()
a, b
(1.0, 1.0)
Decision boundary in the input space. Note that we have to convert logits to probabilities:
def prediction(x, y):
p = F.softmax(net(torch.tensor([[x, y]])), dim=1)
return p[0, 1].item()
Show code cell source
from matplotlib.colors import LinearSegmentedColormap
# Define your custom colormap
colors = ["C0", "C1"]
n_bins = 100
cm = LinearSegmentedColormap.from_list(name="", colors=colors, N=n_bins)
# Create a grid of points
N = 100
x = np.linspace(-1.5, 1.5, N)
y = np.linspace(-1.5, 1.5, N)
X, Y = np.meshgrid(x, y)
# Calculate function values for each point on the grid
Z = np.zeros_like(X)
for i in range(N):
for j in range(N):
Z[i, j] = prediction(float(X[i, j]), float(Y[i, j]))
# Create a color plot using the custom colormap
plt.pcolormesh(X, Y, Z, shading='auto', cmap=cm)
plt.colorbar()
plt.xlabel('X')
plt.ylabel('Y')
plt.scatter(x0[:, 0], x0[:, 1], s=10.0, label=0, color="C0", edgecolor="black")
plt.scatter(x1[:, 0], x1[:, 1], s=10.0, label=1, color="C1", edgecolor="black")
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.legend()
plt.axis('equal');
plt.xlim(-1.5, 1.5)
plt.ylim(-1.5, 1.5)
plt.show();

Figure. Probability assigned by the trained network on the input space. Note that we were able to extend linear classification to learning a nonlinear decision boundary. Using ReLU activation here instead of Tanh results in a boundary with sharp corners. This can be thought of as a manifestation of inductive bias.
Remark. Cross entropy is defined as \(H(p, \hat{p}) = -\mathbb{E}_{p}[\log \hat{p}]\) where \(p\) is the true probability and \(\hat{p}\) is the modeled probabilities. This is equivalent to NLL when \(p\) are one-hot probability vectors, i.e. we calculate the average \(-\log \hat{p}_y\) where \(y\) is the target class. Thus, any classification model trained with cross-entropy on hard labels maximizes the likelihood of the training dataset.
In practice, we convert class scores into probabilities using the softmax function. The PyTorch implementation F.cross_entropy reflects this. The true probability vector \(p\) can be of shape \((B,)\) where \(B\) is the number of inputs where \(p_i = 0, 1, \ldots, K-1\) for \(K\) classes (hard labels), or \((B, K)\) where \(p_{ij} \in [0, 1]\) containing probabilities for class \(j\) (soft labels).
import torch
import torch.nn.functional as F
B = 32 # num examples
K = 3 # num classes
s = torch.randn(B, K) # logits (class scores)
p = torch.randint(0, K, size=(B,)) # hard labels => one-hot true probas
F.cross_entropy(input=s, target=p) # expects logits (!)
tensor(1.5596)
F.cross_entropy calculates cross-entropy with softmax probas:
q = F.softmax(s, dim=1)
-torch.log(q[range(B), p]).mean()
tensor(1.5596)
Loss minimization#
For each choice of model parameters \(\boldsymbol{\Theta}\), we defined the empirical risk \(\mathcal{L}_\mathcal{D}(\boldsymbol{\Theta})\) as an unbiased estimate of the true risk \(\mathcal{L}(\boldsymbol{\Theta})\) defined as the expected loss on the underlying distribution given the model \(f_{\boldsymbol{\Theta}}\) (see (1)). It is natural to ask whether this is an accurate estimate. There are two things to watch out for when training our models:
Overfitting. This is characterized by having low empirical risk, but high true risk. This can happen if the dataset is too small to be representative of the true distribution. Or if the model is too complex. In the latter case, the model will interpolate the sample, but will have arbitrary behavior between datapoints.
Underfitting. Here the empirical risk, and thereby the true risk, is high. This can happen if the model is too weak (low capacity, or too few parameters) — e.g. too strong regularization. Or if the optimizer is not configured well (e.g. wrong learning rate), so that the parameters \(\boldsymbol{\Theta}\) found are inadequate even on the training set.
Observe that MLE is by definition prone to overfitting. We rely on smoothness between data points for the model to generalize to test data. It is important to analyze the error between different training samples. A well-trained model should not look too different between samples. But we also don’t want it to have the same errors with different data! (Fig. 6)
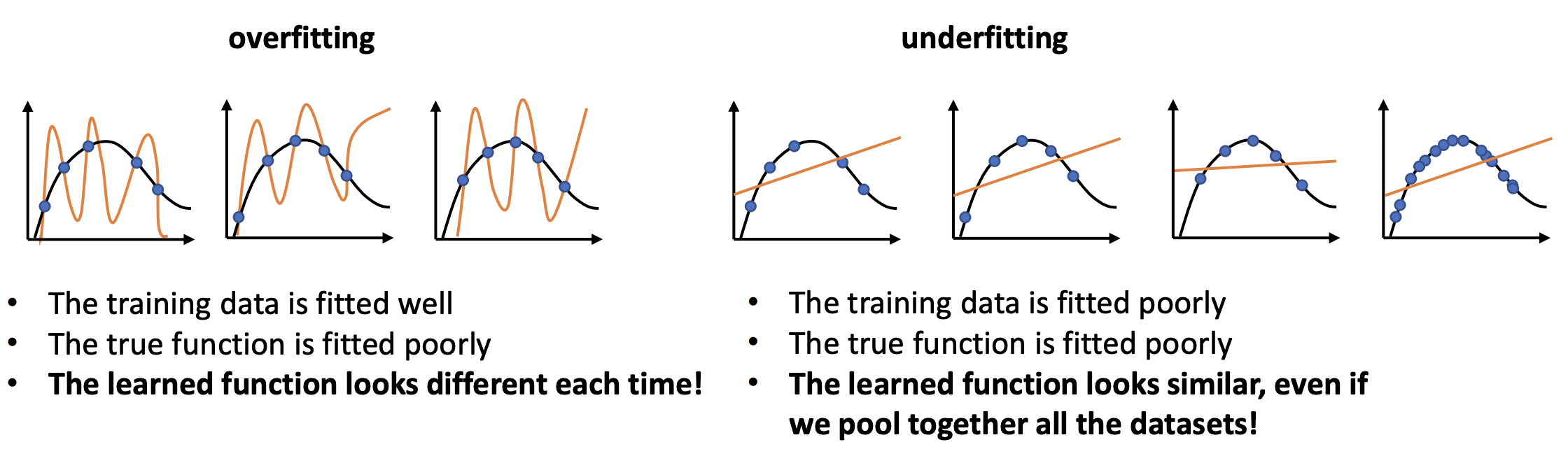
Fig. 6 Drawing of a model that overfits and underfits the distribution. Source: [CS182-lec3]#
Bias-variance tradeoff#
Let us analyze the squared error of trained models. We will assume the existence of a a ground truth function \(f\). Let \(f_{\mathcal{D}}\) be the function obtained by the training process over the sample \(\mathcal{D}.\) Let \(\bar{f}\) be the expected function when drawing fixed sized samples \(\mathcal{D} \stackrel{\text{iid}}{\sim} P^N\) where \(N = |\mathcal{D}|\) and \(P\) is the underlying data distribution. In other words, \(\bar{f}\) is an ensemble of trained models weighted by the probability of its training dataset. Then:
The middle term vanishes by writing it as:
Observe that the variance term describes variability of models as we re-run the training process without actually looking into the true function. The bias term, on the other hand, looks at the error of the ensemble \(\bar{f}\) from the true function \(f.\) These can be visualized as manifesting in the left and right plots respectively of Fig. 6.
Remark. This derivation ignores target noise which is relevant in real-world datasets. Here we have a distribution \(p(y \mid \boldsymbol{\mathsf{x}})\) around the target which we have to integrate over to get the expected target. See these notes for a more careful treatment.
Classical tradeoff. There is a tradeoff with respect to model complexity for fixed \(n.\) If we increase model complexity, these models will fit each sample too well that it captures even sampling noise. However, these cancels out over many samples resulting in low bias. Overfitting occurs because we get a model that performs well on the training sample, but may not perform well on a test sample due to high variability. On the other hand, simpler models tend to have high bias and underfits any sample of the dataset. Note that using a sufficiently large sample size for a fixed model class can decrease variance as more data will result in drowning out noise. But bias does not go away no matter how much data we have! [Bar91] provides an explicit tradeoff between data and network size for a certain class of fully-connected neural networks and training algorithm:
where \(M\) is the number of nodes, \(N = |\mathcal{D}|\) is the number of training observations, and \(d\) is the input dimension. Here the first term corresponds to the bias which is data independent, while the second term corresponds to the variance which increases with network size and decreases with data. This bound also highlights the curse of dimensionality. The input dimension contributes linearly to the error, while data only decreases error at the rate \(O(\log N / N)\).
Double descent. Moreover, there is the phenomenon of double descent [NKB+19] observed in most networks used in practice where both bias and variance go down with excess complexity. See this interview by one of the authors. One intuition is that near the interpolation threshold where there is roughly a 1-1 correspondence between all the sample datasets and the models, small changes in the dataset lead to large changes in the model. This is the critical regime in the classical case where overfitting occurs. Having more data destroys this 1-1 correspondence, which is covered by the classical tradeoff described above.
Double descent occurs in the opposite case where we have much more parameters than data (Fig. 7). SGD gets to focus more on what it wants to do, i.e. search for flat minima [KMN+16a], since it is not constrained to use the full model capacity. Note that the double descent curve is more prominent when there is label noise. In this case, the complexity tradeoff is sharper in the critical regime since there is less redundancy in parameters of the model when the dataset is harder to learn.
Remark. Models around with weights flat minimas have validation errors that are much more stable to perturbation in the weights and, as such, tend to be smooth between data points [HS97]. SGD is discussed in the next chapter.
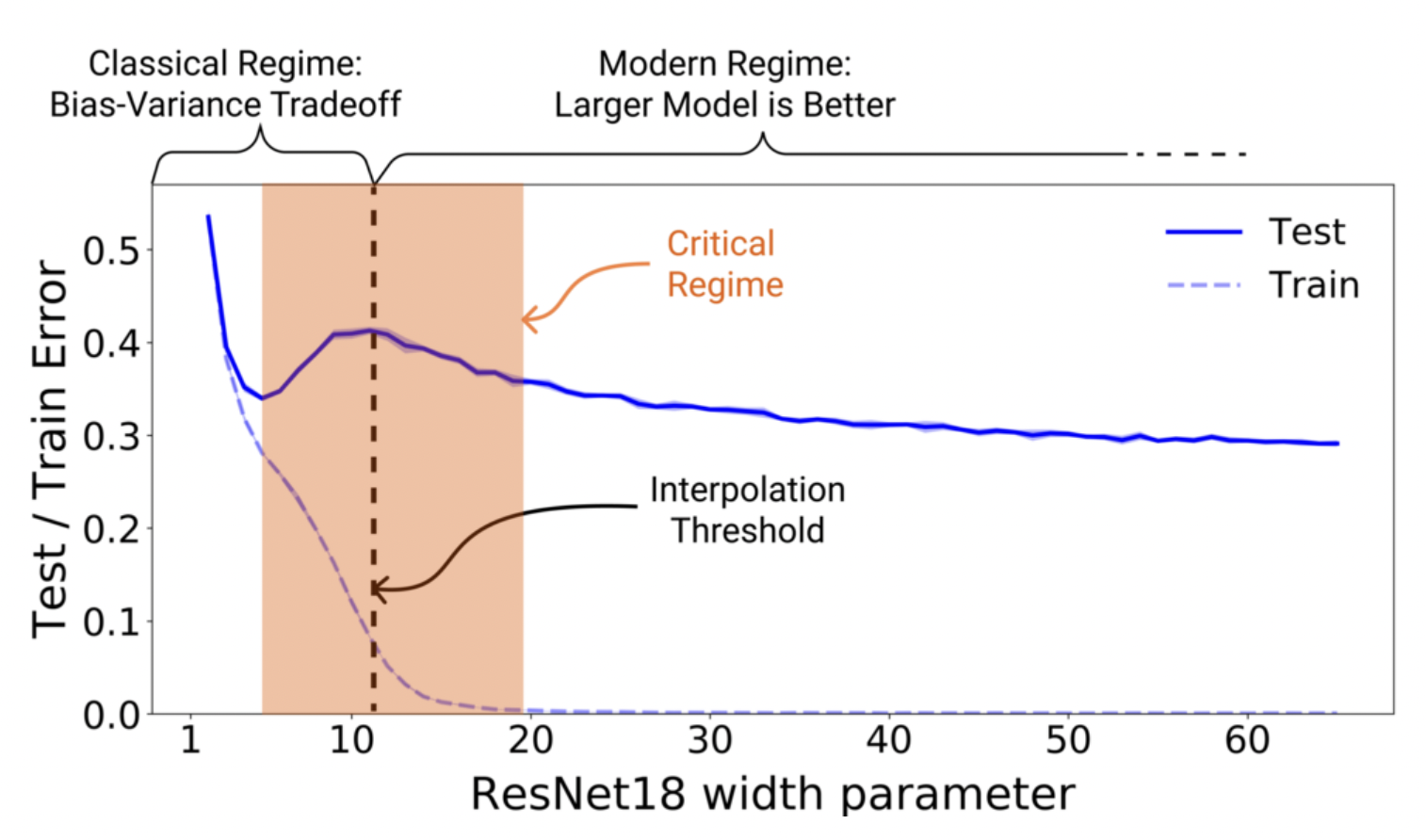
Fig. 7 Double descent for ResNet18. The width parameter controls model complexity. Source: [NKB+19]#
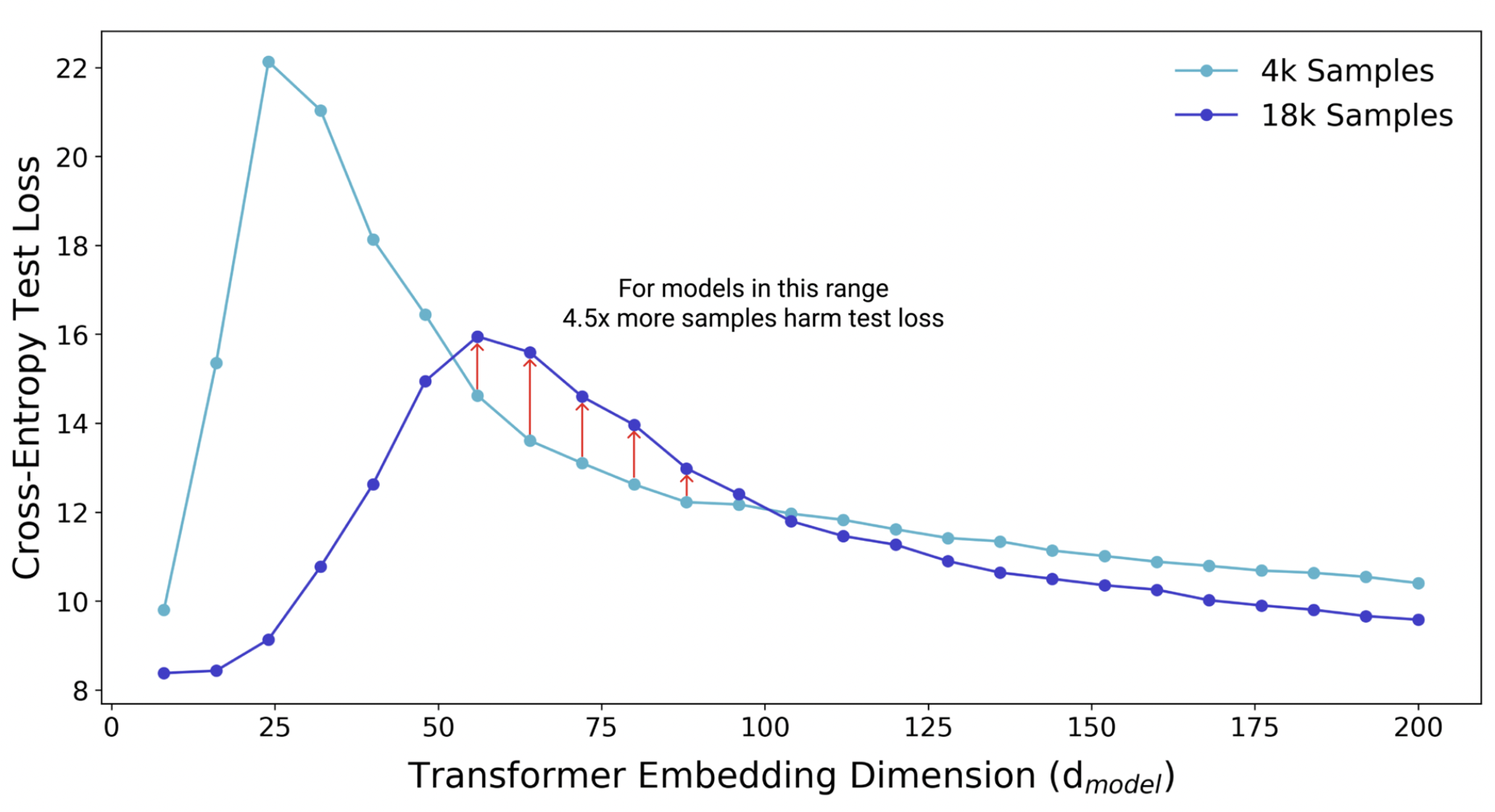
Fig. 8 Additional data increases model variance within the critical regime. More data shifts the interpolation threshold to the right, resulting in worse test performance compared to the same model trained on a smaller sample. Increasing model complexity improves test performance. Source: [NKB+19]#
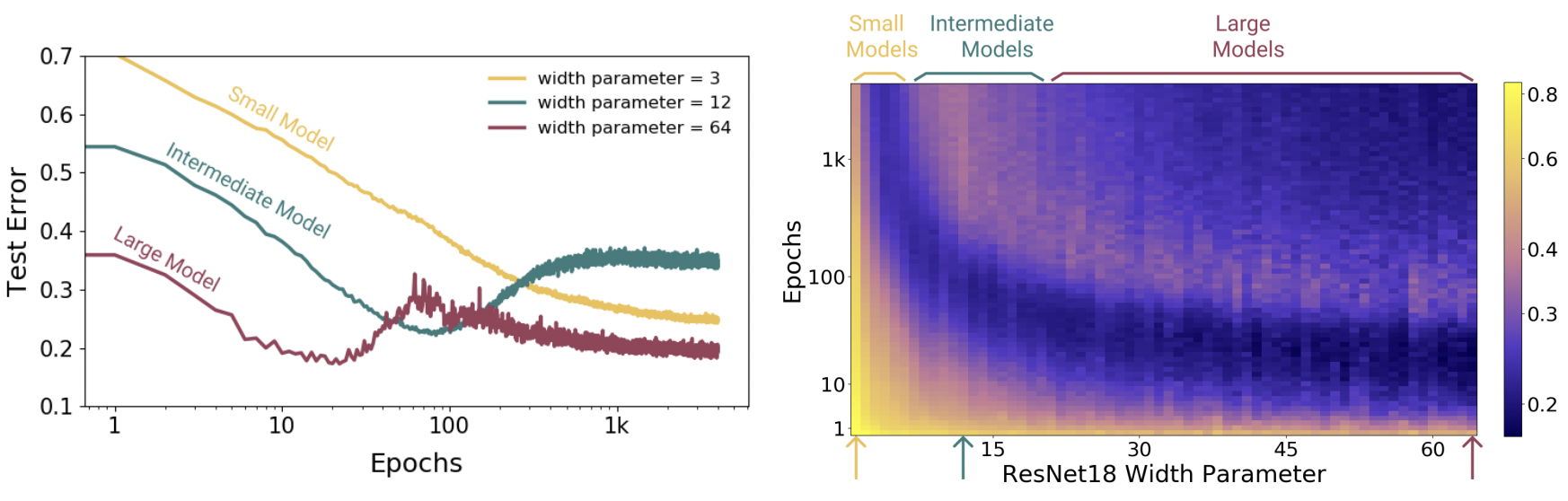
Fig. 9 Epoch dimension to double descent. Models are ResNet18s on CIFAR10 with 20% label noise, trained using Adam with learning rate 0.0001, and data augmentation. Left: Training dynamics for models in three regimes. Right: Test error vs. Model size × Epochs. Three slices of this plot are shown on the left. Source: [NKB+19]#
Regularization#
How do we control bias and variance? There are two solutions: (1) getting more data, (2) tuning model complexity. More data decreases variance but has no effect on bias. Increasing complexity decreases bias but increases variance. Since biased models do not scale well with data, a good approach is to start with a complex model and decrease complexity it until we get a good tradeoff. This approach is called regularization. Regularization can be thought of as a continuous knob on complexity that smoothly restricts model class.
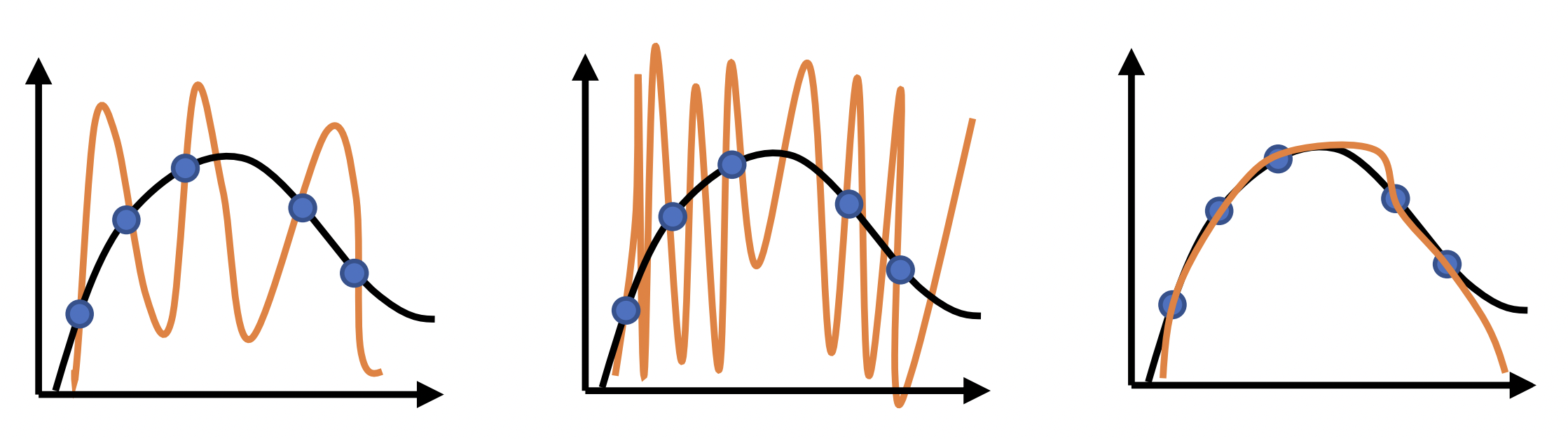
Fig. 10 All these have zero training error. But the third one is better. This is because resampling will result in higher empirical risk for the first two, which implies high true risk. Source: [CS182-lec3]#
Bayesian perspective. High variance occurs when data does not give enough information to identify parameters. If we provide enough information to disambiguate between (almost) equally good models, we can pick the best one. One way to provide more information is to make certain parameter values more likely. In other words, we assign a prior on the parameters. Since the optimizer picks parameter values based on the loss, we can look into how we can augment the loss function to do this. Instead of MLE, we do a MAP estimate for \(\boldsymbol{\Theta}\):
Note we used independence between params and input. This also means that the term for the input is an additive constant, and therefore ignored in the resulting loss:
Can we pick a prior that makes the smoother function more likely? This can be done by assuming a distribution on \(\boldsymbol{\Theta}\) that assigns higher probabilities to small weights: e.g. \(p(\boldsymbol{\Theta}) \sim \mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}).\) This may result in a smoother fit (Fig. 10c). Solving the prior:
where \(\lambda > 0\) and \(\lVert \cdot \rVert\) is the L2 norm. Since we choose the prior, \(\lambda\) effectively becomes a hyperparameter that controls the strength of regularization. The resulting loss has the L2 regularization term:
The same analysis with a Laplace prior results in the L1 regularization term:
Remark. It makes sense that MAP estimates result in weight penalty since the weight distribution is biased towards low values. Intuitively, large weights means that the network is memorizing the training dataset, and we get sharper probability distributions with respect to varying input features. Since the class of models are restricted to having low weights, this puts a constraint on the model class, resulting in decreased complexity. Note that these regularizers introduce hyperparameters that we have to tune well. See experiments below.
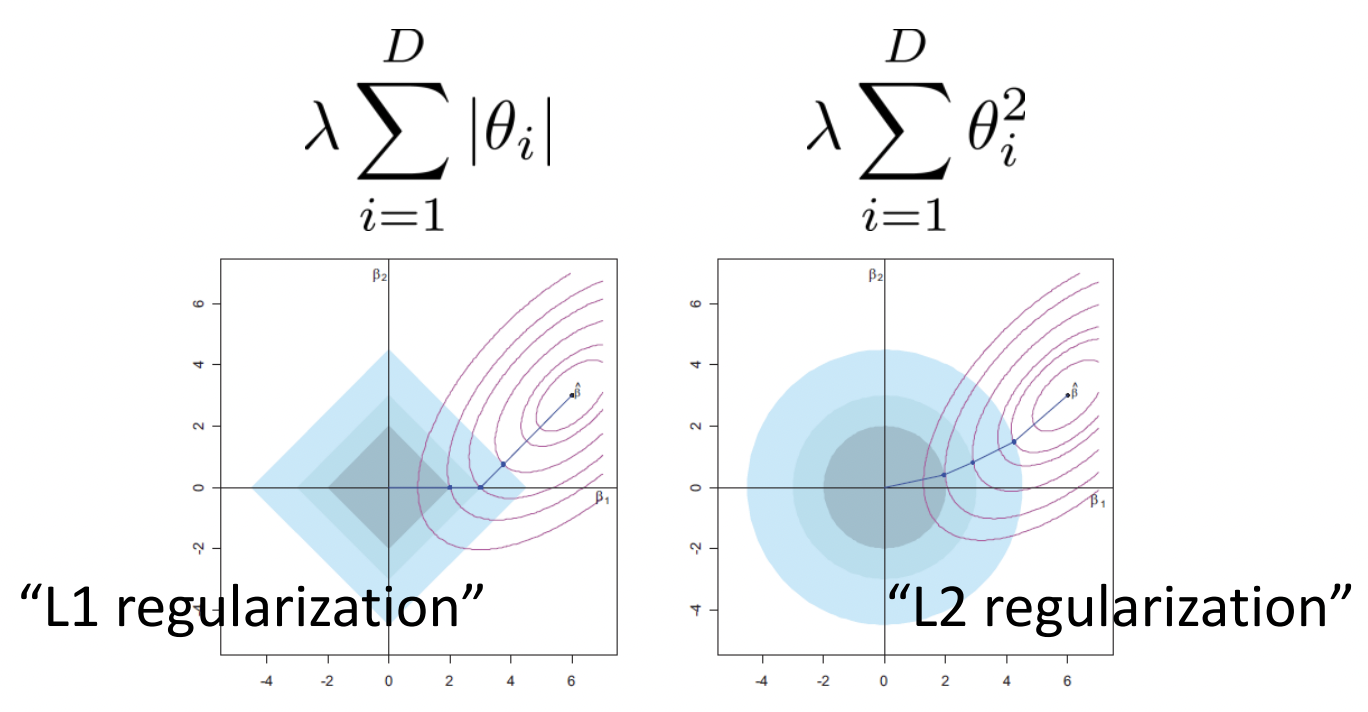
Fig. 11 Minimizing both prediction loss and regularization loss surfaces. L1 results in sparse weights since moving along the axes results in minimal increase in the prediction loss with maximal decrease in regularization loss. Source: [CS182-lec3]#
Other perspectives. The numerical perspective is that adding a regularization term in the loss can make underdetermined problems well-determined. The optimization perspective is that the regularizer makes the loss landscape easier to search. Paradoxically, regularizers can sometimes reduce underfitting if it was due to poor optimization! Other types of regularizers are ensembling (e.g. Dropout) and gradient penalty (for GANs).
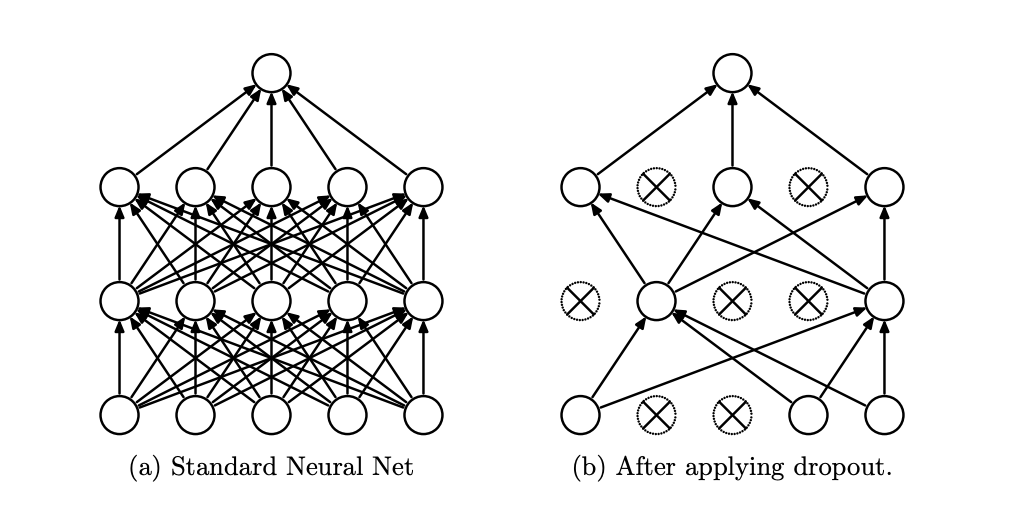
Fig. 12 [SHK+14] Dropout drops random units with probability \(p\) at each step during training. This prevents overfitting by reducing the co-adaptation of neurons during training, which in turn limits the capacity of the model to fit noise in the training data. Since only \(1 - p\) units are present during training, the activations are scaled by \(\frac{1}{1 - p}\) to match test behavior.#
Experiments#
x = torch.linspace(-10, 10, 1000)
y = 3 * torch.sin(x) + torch.cos(torch.pi * x)
def model(width, sample_size, alpha=0.0, x=x, y=y):
"""Fitting a wide fully connected ReLU network."""
x = x.reshape(-1, 1)
y = y.reshape(-1, 1)
N = torch.randint(0, 1000, size=(sample_size,))
N = torch.sort(N)[0]
xs = x[N]
ys = y[N]
net = nn.Sequential(
nn.Linear(1, width),
nn.Tanh(),
nn.Linear(width, 1)
)
theta = net.parameters()
optim = torch.optim.Adam(theta, lr=0.1, weight_decay=alpha)
for _ in range(100):
loss = F.mse_loss(ys, net(xs))
loss.backward()
optim.step()
optim.zero_grad()
return net(x).reshape(-1).detach().cpu().numpy()
def variance(sample_preds):
p_bar = sum(sample_preds) / len(sample_preds)
return sum([((p_bar - p) ** 2).mean() for p in sample_preds]) / len(sample_preds)
def bias(sample_preds):
p_bar = sum(sample_preds) / len(sample_preds)
return ((p_bar - y.numpy()) ** 2).mean()
Decreasing model complexity decreases variance:
Show code cell source
def reset_seed():
np.random.seed(0)
torch.manual_seed(0)
def plot_model(ax, width=6, sample_size=6, alpha=0.0, count=300):
sample_preds = []
for i in range(count):
p = model(width, sample_size, alpha)
if i < 100:
ax.plot(x, p, alpha=0.5, color="C0")
sample_preds.append(p)
var = variance(sample_preds)
b = bias(sample_preds)
title = f"var={var:.2f}, bias={b:.2f} \n width={width}, n={sample_size}"
if alpha > 0:
title += f", $\lambda$={alpha:.0e}"
ax.set_title(title)
ax.plot(x, y, color="black", linewidth=2)
ax.set_ylim(-8, 8)
reset_seed()
fig, ax = plt.subplots(1, 3, figsize=(12, 3.5))
plot_model(ax[0], width=16, sample_size=12)
plot_model(ax[1], width=4, sample_size=12)
plot_model(ax[2], width=2, sample_size=12)
fig.tight_layout()

Regularization decreases variance and increases bias:
Show code cell source
reset_seed()
fig, ax = plt.subplots(1, 3, figsize=(12, 3.5))
plot_model(ax[0], width=16, sample_size=12, alpha=0.1)
plot_model(ax[1], width=4, sample_size=12, alpha=0.1)
plot_model(ax[2], width=2, sample_size=12, alpha=0.1)
fig.tight_layout()

More data decreases variance so that bias dominates:
Show code cell source
reset_seed()
fig, ax = plt.subplots(1, 3, figsize=(12, 3.5))
plot_model(ax[0], width=16, sample_size=12)
plot_model(ax[1], width=16, sample_size=24)
plot_model(ax[2], width=16, sample_size=36)
fig.tight_layout()

Regularization when too strong can make low complexity models underfit:
Show code cell source
reset_seed()
fig, ax = plt.subplots(1, 3, figsize=(12, 3.5))
plot_model(ax[0], width=4, sample_size=12, alpha=0.1)
plot_model(ax[1], width=4, sample_size=12, alpha=1.0)
plot_model(ax[2], width=4, sample_size=12, alpha=10.0)
fig.tight_layout()

Remark. Notice that complex models benefit more with regularization and scale better with data compared to simple models. The experiments show that starting with complex models followed by regularization is a valid approach.
Train-validation split#
How do we know if we are overfitting or underfitting? Note that we do not have access to the ground truth function \(f\) (otherwise there is no point in doing ML) or the expected model \(\bar{f}\) (too expensive to estimate). How do we select algorithm or hyperparameters? This can be done simply by reserving a subset of the dataset called the validation set for estimating the true risk. The validation performance is used for choosing hyperparameters and tweaking the model class. Recall that the training dataset is used to minimize the empirical risk. In terms of train and validation loss:
Overfitting is characterized by significant \(\mathcal{L}_{\mathcal{D}_{\text{train}}}(\boldsymbol{\Theta}) \ll \mathcal{L}_{\mathcal{D}_{\text{val}}}(\boldsymbol{\Theta})\).
Underfitting is characterized by \(\mathcal{L}_{\mathcal{D}_{\text{train}}}(\boldsymbol{\Theta})\) not decreasing low enough (Fig. 13).
The training and validation curves are generated by \((t, \mathcal{L}_{\mathcal{D}_{\text{train}}}(\boldsymbol{\Theta}^t))\) and \((t, \mathcal{L}_{\mathcal{D}_{\text{val}}}(\boldsymbol{\Theta}^t))\) for steps \(t\) during training (Fig. 13). The model only sees the train set during training. Meanwhile, the model is evaluated on the same validation set getting controlled results. Note that modifying training hyperparameters between runs means that the validation set is now being overfitted. Techniques such as k-fold cross-validation or mitigates this, but can be expensive for training large models. Training ends with a final set of parameters \(\hat{\boldsymbol{\Theta}}.\)
Finally, a separate test set is used to report the final performance. The loss on the test set \(\mathcal{L}_{\mathcal{D}_{\text{test}}}(\hat{\boldsymbol{\Theta}})\) acts as the final estimate of the true risk of the trained model. It is best practice that the test evaluation is done exactly once. Note that the training, validation, and test sets are chosen to be disjoint.
Remarks. Regularization tends to flatten out the classical U-shape validation curve that occurs before epoch-wise double descent (Fig. 9) where the model overfits. Assuming the model is sufficiently complex so that there is little bias, underfitting can indicate a problem with the optimizer (e.g. learning rate). We will see in the next chapter that training loss curves stuck to values away from zero may indicate a problem with the optimizer (stuck in a plateau, or bad local optima).
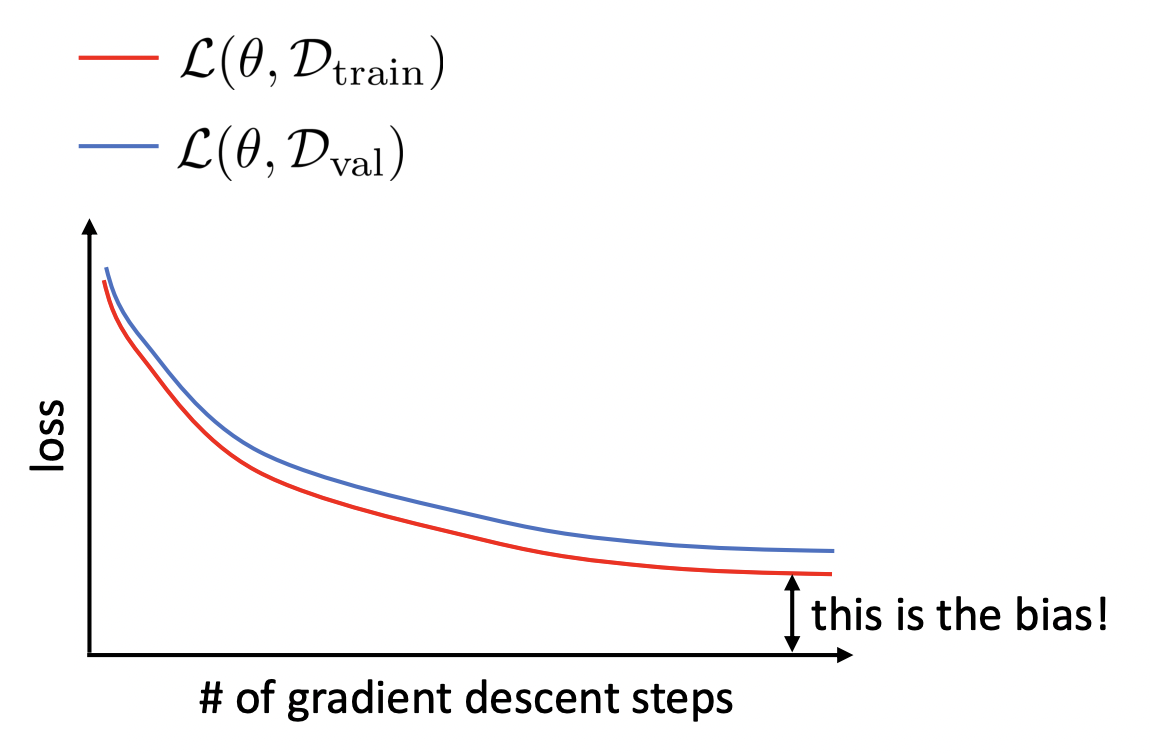
Fig. 13 Train and validation loss curves during training. Gap in train curve can indicate bias or a problem with the optimizer. Source: [CS182-lec3]#
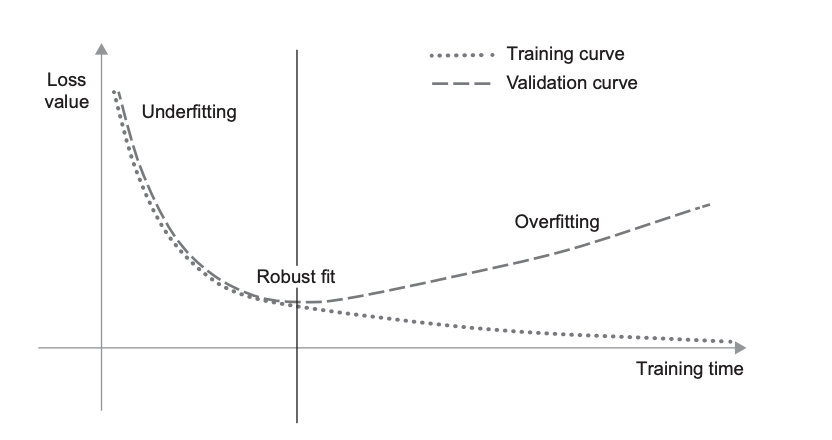
Fig. 14 Canonical train-validation loss curves. Source: [Cho21]#
Remark. A commonly used technique is early stopping which stops training once the validation curves stops improving after a set number of steps. One consequence of epoch-wise double descent is that early stopping only helps in the relatively narrow parameter regime of critically parameterized models (Fig. 9)! In fact, practical experience shows that early stopping results in overfitting the validation set (Fig. 15).

Fig. 15 Top Kaggle GMs recommending against the use of early stopping. Source: [video]#
Appendix: BCE loss#
Here we introduce the BCE loss which you might encounter in the wild. This turns out to be just cross-entropy but for binary classification with scalar-valued models. Another goal of this section is to show that conceptually simple things in ML can be confusing due to implementation details.
For binary classification, since \(p_0 + p_1 = 1\), it suffices to compute the probability for the positive class \(p_1\). Hence, we should be able to train a scalar valued NN to compute the probabilities. In this case, the cross-entropy loss can be calculated using \(p_1\):
Let \(\boldsymbol{\mathsf{s}} = f(\boldsymbol{\mathsf{x}}) \in \mathbb{R}^2\) be the network output. Recall that the softmax probabilities are given by:
Then, the probability of the positive class can be written as:
where \(\Delta s := s_1 - s_0.\) This can now be used to calculate the cross-entropy by using
which is more numerically stable than calculating the two operations sequentially. Note that \(\Delta s = (\boldsymbol{\theta}_1 - \boldsymbol{\theta}_0)^\top \boldsymbol{\mathsf{z}} + (b_1 - b_0)\) since the logits layer is linear. Thus, we can train an equivalent scalar-valued model with these fused weights that models \(\Delta s.\) This model predicts the positive class whenever \(\Delta s \geq 0,\) i.e. \(s_1 \geq s_0.\) The scalar-valued model can then be converted to the two-valued model by assigning zero weights and bias to the negative class.
Remark. This is another nice property of using the exponential to convert scores to probabilities, i.e. it converts a sum to a product, allowing fusing the weights of the logits layer to get one separating hyperplane.
Appendix: Weak supervision#
In this section, we apply what we learned in this notebook to implement weak supervision. The idea of weak supervision is that for each data point there is a latent true label that we do not have access to (even during training), instead we can utilize weak signals from user-defined labeling functions (LFs).
LFs can be thought of as heuristic rules that can be applied to a large subset of the data. In case the LF is not applicable, then the function simply abstains from making a prediction. Note that this is a realistic scenario, it’s easier to describe rules than to manually annotate a large number of data. LFs provides noisy, less expensive labels, which can be useful when used to train noise-aware discriminative models.
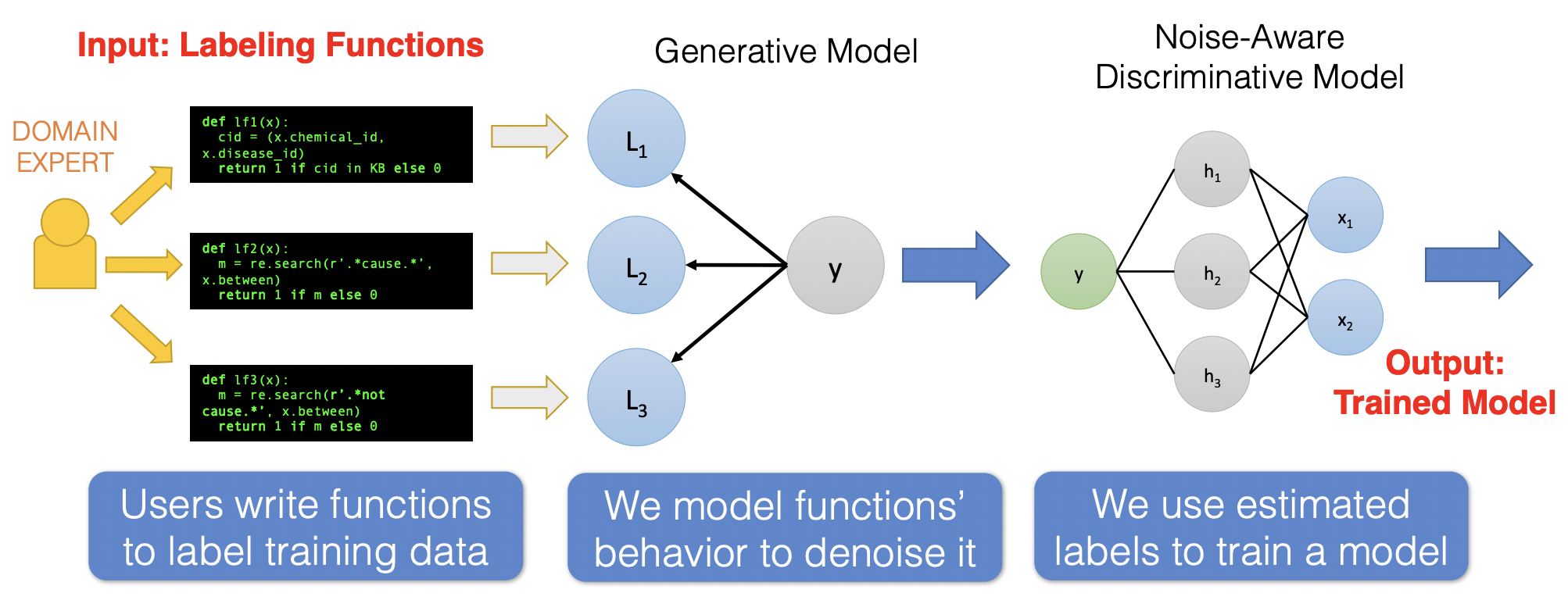
Fig. 16 Pipeline for training a model based on weakly supervised labels. The third image is flipped (i.e. the flow of prediction is right to left.) These two tasks will be implemented in this notebook. Source#
Remark. The material here is an exposition and implementation of the data programming approach to weak supervision using LFs described in [RSW+17].
Toy example#
Our task is to classify whether a sentence is a question or a quote. We will use true labels to evaluate the train and validation performance of the model. But this will not be used during training. In practice, we have a small labeled dataset for validation, that is a part of a large unlabeled dataset, which we want to somehow use for training. The toy dataset consists of 88 sentences:
data = [
"What would you name your boat if you had one? ",
"What's the closest thing to real magic? ",
"Who is the messiest person you know? ",
"What will finally break the internet? ",
"What's the most useless talent you have? ",
"What would be on the gag reel of your life? ",
...
]
Show code cell source
data = [
"What would you name your boat if you had one? ",
"What's the closest thing to real magic? ",
"Who is the messiest person you know? ",
"What will finally break the internet? ",
"What's the most useless talent you have? ",
"What would be on the gag reel of your life? ",
"Where is the worst smelling place you've been?",
"What Secret Do You Have That No One Else Knows Except Your Sibling/S?"
"What Did You Think Was Cool Then, When You Were Young But Isn’t Cool Now?"
"When Was The Last Time You Did Something And Regret Doing It?"
"What Guilty Pleasure Makes You Feel Alive?"
"Any fool can write code that a computer can understand. Good programmers write code that humans can understand.",
"First, solve the problem. Then, write the code.",
"Experience is the name everyone gives to their mistakes.",
" In order to be irreplaceable, one must always be different",
"Java is to JavaScript what car is to Carpet.",
"Knowledge is power.",
"Sometimes it pays to stay in bed on Monday, rather than spending the rest of the week debugging Monday’s code.",
"Perfection is achieved not when there is nothing more to add, but rather when there is nothing more to take away.",
"Ruby is rubbish! PHP is phpantastic!",
" Code is like humor. When you have to explain it, it’s bad.",
"Fix the cause, not the symptom.",
"Optimism is an occupational hazard of programming: feedback is the treatment. " ,
"When to use iterative development? You should use iterative development only on projects that you want to succeed.",
"Simplicity is the soul of efficiency.",
"Before software can be reusable it first has to be usable.",
"Make it work, make it right, make it fast.",
"Programmer: A machine that turns coffee into code.",
"Computers are fast; programmers keep it slow.",
"When I wrote this code, only God and I understood what I did. Now only God knows.",
"A son asked his father (a programmer) why the sun rises in the east, and sets in the west. His response? It works, don’t touch!",
"How many programmers does it take to change a light bulb? None, that’s a hardware problem.",
"Programming is like sex: One mistake and you have to support it for the rest of your life.",
"Programming can be fun, and so can cryptography; however, they should not be combined.",
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the Universe trying to produce bigger and better idiots. So far, the Universe is winning.",
"Copy-and-Paste was programmed by programmers for programmers actually.",
"Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live.",
"Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.",
"Algorithm: Word used by programmers when they don’t want to explain what they did.",
"Software and cathedrals are much the same — first we build them, then we pray.",
"There are two ways to write error-free programs; only the third works.",
"If debugging is the process of removing bugs, then programming must be the process of putting them in.",
"99 little bugs in the code. 99 little bugs in the code. Take one down, patch it around. 127 little bugs in the code …",
"Remember that there is no code faster than no code.",
"One man’s crappy software is another man’s full-time job.",
"No code has zero defects.",
"A good programmer is someone who always looks both ways before crossing a one-way street.",
"Deleted code is debugged code.",
"Don’t worry if it doesn’t work right. If everything did, you’d be out of a job.",
"It’s not a bug — it’s an undocumented feature.",
"It works on my machine.",
"It compiles; ship it.",
"There is no Ctrl-Z in life.",
"Whitespace is never white.",
"What’s your favorite way to spend a day off?",
"What type of music are you into?",
"What was the best vacation you ever took and why?",
"Where’s the next place on your travel bucket list and why?",
"What are your hobbies, and how did you get into them?",
"What was your favorite age growing up?",
"Was the last thing you read?",
"Would you say you’re more of an extrovert or an introvert?",
"What's your favorite ice cream topping?",
"What was the last TV show you binge-watched?",
"Are you into podcasts or do you only listen to music?",
"Do you have a favorite holiday? Why or why not?",
"If you could only eat one food for the rest of your life, what would it be?",
"Do you like going to the movies or prefer watching at home?",
"What’s your favorite sleeping position?",
"What’s your go-to guilty pleasure?",
"In the summer, would you rather go to the beach or go camping?",
"What’s your favorite quote from a TV show/movie/book?",
"How old were you when you had your first celebrity crush, and who was it?",
"What's one thing that can instantly make your day better?",
"Do you have any pet peeves?",
"What’s your favorite thing about your current job?",
"What annoys you most?",
"What’s the career highlight you’re most proud of?",
"Do you think you’ll stay in your current gig awhile? Why or why not?",
"What type of role do you want to take on after this one?",
"Are you more of a work to live or a live to work type of person?",
"Does your job make you feel happy and fulfilled? Why or why not?",
"How would your 10-year-old self react to what you do now?",
"What do you remember most about your first job?",
"How old were you when you started working?",
"What’s the worst job you’ve ever had?",
"What originally got you interested in your current field of work?",
"Have you ever had a side hustle or considered having one?",
"What’s your favorite part of the workday?",
"What’s the best career decision you’ve ever made?",
"What’s the worst career decision you’ve ever made?",
"Do you consider yourself good at networking?"
]
Then, we can define labeling functions. Notice that these are user-defined and requires some domain expertise to be effective:
QUESTION = 1
QUOTE = -1
ABSTAIN = 0
def lf_keyword_lookup(x):
keywords = ["why", "what", "when", "who", "where", "how"]
return QUESTION if any(word in x.lower() for word in keywords) else ABSTAIN
def lf_char_length(x):
return QUOTE if len(x) > 100 else ABSTAIN
def lf_regex_endswith_dot(x):
return QUOTE if x.endswith(".") else ABSTAIN
Applying this to our dataset we get the \(\Lambda_{ij}\) matrix. We will also assign the true label:
import pandas as pd
df = pd.DataFrame({"sentences": data})
df["LF1"] = df.sentences.map(lf_keyword_lookup)
df["LF2"] = df.sentences.map(lf_char_length)
df["LF3"] = df.sentences.map(lf_regex_endswith_dot)
df["y"] = df.sentences.map(lambda x: 1 if x.strip().endswith("?") else -1)
df.head()
| sentences | LF1 | LF2 | LF3 | y | |
|---|---|---|---|---|---|
| 0 | What would you name your boat if you had one? | 1 | 0 | 0 | 1 |
| 1 | What's the closest thing to real magic? | 1 | 0 | 0 | 1 |
| 2 | Who is the messiest person you know? | 1 | 0 | 0 | 1 |
| 3 | What will finally break the internet? | 1 | 0 | 0 | 1 |
| 4 | What's the most useless talent you have? | 1 | 0 | 0 | 1 |
Note that LF2 is intuitively not a good LF function. Indeed, we can look at the strength of the signals of each LF by comparing it with the true label. A labeling function is characterized by its coverage and accuracy (i.e. given it did not abstain):
# Note: the ff. shows *latent* LF parameters
print(f"coverage: {(df.LF1 != 0).mean():.3f} acc: {(df[df.LF1 != 0].LF1 == df[df.LF1 != 0].y).mean():.3f}")
print(f"coverage: {(df.LF2 != 0).mean():.3f} acc: {(df[df.LF2 != 0].LF2 == df[df.LF2 != 0].y).mean():.3f}")
print(f"coverage: {(df.LF3 != 0).mean():.3f} acc: {(df[df.LF3 != 0].LF3 == df[df.LF3 != 0].y).mean():.3f}")
coverage: 0.545 acc: 0.750
coverage: 0.114 acc: 1.000
coverage: 0.432 acc: 1.000
Remark. Note that we generally do not have access to true labels for a representative sample of our dataset. Hence, even estimating the parameters of our LFs are not possible. The following sections will deal with algorithms for estimating these parameters as well as training a machine learning model with noisy labels.
Basic theory#
Here we will consider binary classification, although the method can be easily extended to the multiclass setting. For each data point \(\boldsymbol{\mathsf{x}} \in \mathscr{X}\) the latent true label is denoted by \(y \in \mathscr{Y} = \{-1, +1\}\). We have \(n\) labeling functions \(\lambda_j\colon \mathscr{X} \to \mathscr{Y} \cup \{0\}\) for \(j = 1, \ldots, n.\) In case that the LF is not applicable, then the LF returns \(0\) for abstain. This explains why we augmented the target space with the zero label. So if we have data points \(\boldsymbol{\mathsf{x}}_i\) for \(i = 1, \ldots, m\), then we get an \(m \times n\) matrix of LF outputs \(\Lambda_{ij} = \lambda_j(\boldsymbol{\mathsf{x}}_i)\).
Our first step is to estimate the distribution \(p_{\delta, \gamma}(\Lambda=\lambda(\boldsymbol{\mathsf{x}}), Y=y)\) defined as the probability that LFs output \(\lambda(\boldsymbol{\mathsf{x}}) = (\lambda_1(\boldsymbol{\mathsf{x}}), \ldots, \lambda_n(\boldsymbol{\mathsf{x}}))\) for a test instance \(\boldsymbol{\mathsf{x}}\) with true label \(y\). The parameters are chosen such that the marginal probability \(p(\Lambda_{ij})\) of the observed LF outputs is maximized. This parameters of the model are coverage \(\delta = (\delta_1, \ldots, \delta_n)\) and accuracy \(\gamma = (\gamma_1, \ldots, \gamma_n)\) of each LF. Once the parameters \(\hat{\delta}\) and \(\hat{\gamma}\) have been learned, we can train a noise-aware discriminative model by minimizing the ff. loss function:
where \(\ell\) is the instance loss. This looks like the usual loss except that the contribution for each target is summed over weighted by the probability of the target given the labeling of the input.
Generative model#
For each LF \(\lambda_j\) we assign two parameters \((\delta_j, \gamma_j)\) corresponding to its coverage and accuracy. Coverage \(\delta_j\) is defined as the probability of labeling an input, and accuracy as \(\gamma_j\) as the probability of labeling it correctly. This assumes that the LFs have the same distribution for each label (e.g. not more accurate when the label is positive). Moreover, we assume that LF outputs are independent of each other. Hence,
Our goal therefore is to find parameters that maximize the observed LF outputs for our dataset:
Remark. The assumption that accuracy is independent of true label is strong. Recall that the distributions in the rows of a confusion matrix for a classifier are not generally the same for each true label. This is fixed by having a separate set of LF parameters for each true label. For the multi-class case with \(K\) classes, we have to learn parameters for \(K-1\) entries of each row of the confusion matrix of every LF. For the sake of simplicity, we stick with the idealized case for binary classification.
We implement the above equations using some clever indexing:
import torch
torch.manual_seed(1)
delta = torch.tensor([0.3, 0.3, 0.3, 0.3]) # coverage
gamma = torch.tensor([0.7, 0.6, 0.8, 0.9]) # accuracy
n = 4
L = torch.tensor([
[-1, 0, +1, +1],
[+1, -1, -1, 0],
])
params = torch.stack([
1 - delta, # abstained
delta * gamma, # accurate
delta * (1 - gamma) # inaccurate
], dim=0)
params # Note sum along dim=0 is 1, i.e. sum of all p(λ | y) for λ = -1, 0, 1 is 1.
tensor([[0.7000, 0.7000, 0.7000, 0.7000],
[0.2100, 0.1800, 0.2400, 0.2700],
[0.0900, 0.1200, 0.0600, 0.0300]])
We will use the empirical LF matrix to pick out the appropriate weight given its value:
# p(L | y = +1)
params[L, torch.arange(n)]
tensor([[0.0900, 0.7000, 0.2400, 0.2700],
[0.2100, 0.1200, 0.0600, 0.7000]])
Notice that non-abstained probabilities will flip:
# p(L | y = -1)
params[-L, torch.arange(n)]
tensor([[0.2100, 0.7000, 0.0600, 0.0300],
[0.0900, 0.1800, 0.2400, 0.7000]])
Let \(p_{y=-1} = 0.7\) and \(p_{y=+1} = 0.3\). The marginal probability of the LF outputs for each instance is given by:
py = [0.0, 0.5, 0.5] # zero-index = dummy
p_pos = py[+1] * (params[+L, torch.arange(n)]).prod(dim=1)
p_neg = py[-1] * (params[-L, torch.arange(n)]).prod(dim=1)
p = p_pos + p_neg
p
tensor([0.0022, 0.0019])
Note that we generally have \(m \gg 1\) terms with valuees in \([0, 1].\) So we use \(\log\) to convert the product to a sum:
print(" p(Λ):", p.prod().item())
print("-log p(Λ):", -torch.log(p).sum().item())
p(Λ): 4.107915628992487e-06
-log p(Λ): 12.402594566345215
Simulated LFs#
Generating a toy dataset and simulated values of LFs. Here we also set the prior probability on the labels:
import numpy as np
np.random.seed(1)
m = 10000
LABEL_PROBS = {-1: 0.40, 1: 0.60}
y_true = np.random.choice([-1, 1], size=m, p=[LABEL_PROBS[-1], LABEL_PROBS[1]])
s = 2 * torch.pi * torch.rand(m, 1)
r = 0.5 * (torch.tensor(y_true).view(-1, 1) + 1) # -1 -> r = 0, +1 -> r = 1
x = torch.cat([r * torch.cos(s), r * torch.sin(s)], dim=1) + 0.05 * torch.randn(m, 2)
t = np.linspace(0, 2*np.pi, 100)
x0 = 0.5 * np.cos(t)
x1 = 0.5 * np.sin(t)
x_neg = x[torch.where(torch.tensor(y_true) == -1)]
x_pos = x[torch.where(torch.tensor(y_true) == +1)]
Show code cell source
import matplotlib.pyplot as plt
def plot_dataset(x_neg, x_pos):
m = len(x_neg)
limit = m // 10
plt.scatter(x_neg[:limit, 0], x_neg[:limit, 1], s=2.0, color="C0", label="y = -1")
plt.scatter(x_pos[:limit, 0], x_pos[:limit, 1], s=2.0, color="C1", label="y = 1")
plt.plot(x0, x1, color='black', linewidth=1, linestyle='dashed', label="r = 0.5")
plt.xlabel("x$_0$")
plt.ylabel("x$_1$")
plt.legend()
plt.axis('equal');
plot_dataset(x_neg, x_pos)

Note that radius less than 0.5 determines the label as negative (with high probability):
# 2x - 1: [0, 1] -> [-1, 1]
((2 * (torch.sqrt((x ** 2).sum(dim=1)) >= 0.5).float() - 1).numpy() == y_true).mean()
1.0
We use this to write simulated LFs with given parameters:
def lf_sim(coverage, accuracy):
def predict(x):
m = x.shape[0]
cov_mask = torch.rand(m) < coverage
acc_mask = torch.tensor(np.random.choice([-1, 1], size=sum(cov_mask).item(), p=[1 - accuracy, accuracy]))
y = 2 * (torch.sqrt((x ** 2).sum(dim=1)) >= 0.5).long() - 1
y[cov_mask == 0] = 0
y[cov_mask == 1] *= acc_mask
return y
return predict
# example
p = lf_sim(0.3, 0.8)(x).numpy()
print("cov: ", (p != 0).mean())
print("acc: ", (p[p != 0] == y_true[p != 0]).mean())
print("acc+:", (p[(p != 0) & (y_true == +1)] == y_true[(p != 0) & (y_true == +1)]).mean())
print("acc-:", (p[(p != 0) & (y_true == -1)] == y_true[(p != 0) & (y_true == -1)]).mean())
cov: 0.2974
acc: 0.8012777404169469
acc+: 0.8032511210762332
acc-: 0.7983193277310925
Initializing the empirical LF matrix. Some have fairly low accuracy:
import pandas as pd
lf_params = [(0.30, 0.75), (0.50, 0.65), (0.40, 0.70), (0.20, 0.80), (0.25, 0.90)]
labeling_funcs = [lf_sim(*param) for param in lf_params]
df = pd.DataFrame({"y": y_true})
df["x0"] = x[:, 0].numpy()
df["x1"] = x[:, 1].numpy()
for j, lf in enumerate(labeling_funcs):
df[f"LF{j + 1}"] = lf(x).int().numpy()
print(df.shape)
df.head()
(10000, 8)
| y | x0 | x1 | LF1 | LF2 | LF3 | LF4 | LF5 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | -0.013268 | -1.021874 | -1 | -1 | 0 | 0 | 0 |
| 1 | 1 | -0.162512 | 1.006516 | 0 | 1 | 1 | 0 | 0 |
| 2 | -1 | 0.003852 | 0.141634 | 0 | 0 | 0 | 0 | 0 |
| 3 | -1 | -0.024912 | 0.002939 | -1 | 0 | 0 | 0 | 0 |
| 4 | -1 | 0.058476 | -0.078667 | 0 | 0 | 0 | 0 | 0 |
Splitting for evaluation:
# 80-20
SPLIT_RATIO = 0.80
m = x.shape[0]
x_train = x[:int(SPLIT_RATIO * m)]
x_valid = x[int(SPLIT_RATIO * m):]
y_train = torch.tensor(y_true[:int(SPLIT_RATIO * m)])
y_valid = torch.tensor(y_true[int(SPLIT_RATIO * m):])
Model training#
from tqdm.notebook import tqdm
class GenModel:
def __init__(self, labeling_funcs: list, label_probs: dict):
self.lfs = labeling_funcs
self.py = torch.tensor([0.0, label_probs[1], label_probs[-1]]) # zero-index = dummy
self.params = None
def loss_fn(self, L):
p_pos = self.infer_joint_proba(L, +1)
p_neg = self.infer_joint_proba(L, -1)
p = p_pos + p_neg # Note: p has shape [m,]
return -torch.log(p).mean()
def fit(self, x_train, x_valid=None, bs=32, epochs=1, lr=0.0001, lr_decay=1.0):
"""MLE estimate of coverage and accuracy parameters of LFs."""
L_train = self.lf_outputs(x_train)
L_valid = self.lf_outputs(x_valid) if x_valid is not None else None
m, n = L_train.shape
delta = torch.randn(n, requires_grad=True) # coverage score
gamma = torch.randn(n, requires_grad=True) # accuracy score
delta.retain_grad()
gamma.retain_grad()
history = {"train": [], "valid": [], "valid_steps": []}
checkpoint = (None, np.inf)
try:
for e in tqdm(range(epochs)):
B = torch.randperm(m)
for i in range(m // bs):
batch = B[i * bs: (i + 1) * bs]
# Note: weights are scores => need to convert to probs (p = σ(w))
p_delta = 1. / (1. + torch.exp(-delta))
p_gamma = 1. / (1. + torch.exp(-gamma))
self.params = torch.stack([
1 - p_delta, # abstained
p_delta * p_gamma, # accurate
p_delta * (1 - p_gamma) # inaccurate
], dim=0)
loss = self.loss_fn(L_train[batch])
loss.backward(retain_graph=True)
with torch.no_grad():
delta -= lr * (lr_decay ** (e / epochs)) * delta.grad
gamma -= lr * (lr_decay ** (e / epochs)) * gamma.grad
delta.grad = None
gamma.grad = None
history["train"].append(loss.item())
with torch.no_grad():
if L_valid is not None:
val_loss = self.loss_fn(L_valid)
history["valid"].append(val_loss.item())
history["valid_steps"].append((e + 1) * (m // bs))
if val_loss.item() < checkpoint[1]:
checkpoint = (self.params, val_loss.item())
except KeyboardInterrupt:
print("Training stopped.")
finally:
# Note: model is agnostic to relabeling. Row swap when model confuses +1 and -1.
self.params = checkpoint[0]
if (self.params[1, :] / (1 - self.params[0, :])).mean() < 0.5:
row_swap = torch.tensor([[1, 0, 0], [0, 0, 1], [0, 1, 0]]).float()
self.params = row_swap @ self.params
return history
def predict(self, x):
"""Label inference using p(y | Λ_i)."""
L = self.lf_outputs(x)
p = self.target_cond_proba(+1, L) >= 0.5
return 2 * p.long() - 1
def target_cond_proba(self, y, L):
"""Estimate of target prob given LF observations, i.e. p(y | Λ)."""
p_neg = self.infer_joint_proba(L, -1) # p(Λ_i, y=-1)
p_pos = self.infer_joint_proba(L, +1) # p(Λ_i, y=+1)
p_tot = p_neg + p_pos # p(Λ_i) for i = 1, ..., m
return self.infer_joint_proba(L, y) / p_tot # p(y | Λ_i) = p(Λ_i, y) / p(Λ_i)
def infer_joint_proba(self, L, y: int):
"""Return the estimated joint proba p(Λ_i, y), i.e. the output has shape [m,]."""
n = L.shape[1]
return self.py[y] * self.params[y * L, torch.arange(n)].prod(dim=1) # p(Λ_i, y) = p(Λ_i | y) p(y)
def lf_outputs(self, x):
"""Construct Λ matrix from LFs."""
L = torch.stack([lf(x) for lf in self.lfs], dim=1)
return L.long()
gen_model = GenModel(labeling_funcs, LABEL_PROBS)
history = gen_model.fit(x_train, x_valid, bs=4096, epochs=35000, lr=0.03, lr_decay=0.8)
Show code cell source
plt.plot(history["train"], label="train")
plt.plot(history["valid_steps"], history["valid"], label="valid")
plt.ylabel("loss")
plt.xlabel("step")
plt.legend();

print("latent:")
print([f"{cov:.4f}" for cov, acc in lf_params])
print([f"{acc:.4f}" for cov, acc in lf_params])
latent:
['0.3000', '0.5000', '0.4000', '0.2000', '0.2500']
['0.7500', '0.6500', '0.7000', '0.8000', '0.9000']
Model is able to learn the latent probabilities:
print("estimate:")
print([f"{cov:.4f}" for cov in (1 - gen_model.params[0, :]).tolist()])
print([f"{acc:.4f}" for acc in (gen_model.params[1, :] / (1 - gen_model.params[0, :])).tolist()])
estimate:
['0.2937', '0.4958', '0.3978', '0.1937', '0.2581']
['0.7563', '0.6655', '0.6700', '0.7918', '0.8129']
The trained model can be used to estimate joint probabilities of LF outputs and targets:
l = torch.tensor([[-1, -1, -1, -1, -1]])
print(gen_model.infer_joint_proba(l, +1).item())
print(gen_model.infer_joint_proba(l, -1).item())
1.8203746776634944e-06
0.00025144030223600566
The conditional probabilities of targets given LF outputs sum to 1:
# Simple test that the model learned (without using latent labels):
l = torch.tensor([[-1, -1, -1, -1, -1]])
print(gen_model.target_cond_proba(+1, l).item())
print(gen_model.target_cond_proba(-1, l).item())
0.007187750656157732
0.9928122162818909
Label inference#
Soft labels can be generated for a test input using \(p_{\hat{\theta}}(y \mid \lambda(\boldsymbol{\mathsf{x}}))\) calculated using learned LF parameters. This already takes into account the prior label distribution. In particular, if \(\lambda(\boldsymbol{\mathsf{x}}) = \boldsymbol{0}\), then the model falls back to the prior label distribution. Evaluating using latent labels:
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import f1_score, confusion_matrix, precision_score, recall_score
def evaluate(model, x, y, t=None, verbose=True):
m = x.shape[0]
preds = model.predict(x) if t is None else model.predict(x, t)
f1 = f1_score(y.numpy(), preds.numpy(), average="weighted")
recall = recall_score(y.numpy(), preds.numpy(), average="weighted")
precision = precision_score(y.numpy(), preds.numpy(), average="weighted")
if verbose:
print(confusion_matrix(y.numpy(), preds.numpy()))
return {
"f1": f1,
"recall": recall,
"precision": precision,
"m": m, "message": f"m={m}, f1={f1:.5f}"
}
print(evaluate(gen_model, x_train, y_train)["message"]); print()
print(evaluate(gen_model, x_valid, y_valid)["message"])
[[2016 1156]
[ 823 4005]]
m=8000, f1=0.74990
[[533 287]
[184 996]]
m=2000, f1=0.76153
Noise-aware training#
Noise-aware training amounts to weighting the loss with the estimate of the generative model for each target \({p_{\hat{\theta}}(y \mid \lambda(\boldsymbol{\mathsf{x}}))} = {p_{\hat{\theta}}(y, \lambda(\boldsymbol{\mathsf{x}}))}\, /\, {p_{\hat{\theta}}(\lambda(\boldsymbol{\mathsf{x}}))}.\) This allows us to train a model without labels:
import torch.nn as nn
from tempfile import NamedTemporaryFile
np.random.seed(42); torch.manual_seed(42)
class NoiseAwareTrainer:
def __init__(self, clf, gen_model, labeling_funcs: list):
self.clf = clf
self.lfs = labeling_funcs
self.gen_model = gen_model
def loss_fn(self, L, x):
with torch.no_grad():
p_neg_cond = self.gen_model.target_cond_proba(-1, L)
p_pos_cond = self.gen_model.target_cond_proba(+1, L)
p = torch.concat([p_neg_cond, p_pos_cond], dim=0)
fx = self.clf(x)
s = torch.concat([-1 * fx, 1 * fx], dim=0)
return (torch.log(1 + torch.exp(-s)) * p).mean()
def run(self, x_train, x_valid=None, epochs=10, bs=8, lr=0.001, alpha=0.0, momentum=0.1):
m = x_train.shape[0]
history = {"train": [], "valid": [], "valid_steps": []}
best_loss = np.inf
best_epoch = 0
optim = torch.optim.SGD(self.clf.parameters(), lr=lr, weight_decay=alpha, momentum=momentum)
tmp = NamedTemporaryFile(suffix=".pt", delete=True)
L_train = self.lf_outputs(x_train)
L_valid = self.lf_outputs(x_valid) if x_valid is not None else None
try:
for epoch in tqdm(range(epochs)):
B = torch.randperm(m)
for i in range(m // bs):
batch = B[i * bs: (i + 1) * bs]
loss = self.loss_fn(L_train[batch], x_train[batch])
# gradient step
loss.backward()
optim.step()
optim.zero_grad()
# callbacks
history["train"].append(loss.item())
del loss
torch.cuda.empty_cache()
with torch.no_grad():
if x_valid is not None:
val_loss = loss = self.loss_fn(L_valid, x_valid)
history["valid"].append(val_loss.item())
history["valid_steps"].append((epoch + 1) * (m // bs))
if val_loss < best_loss:
best_loss = val_loss.item()
best_epoch = epoch
torch.save(self.clf.state_dict(), tmp.name)
if epoch - best_epoch > int(0.05 * epochs):
print(f"Early stopping at epoch {epoch}...")
raise KeyboardInterrupt
except KeyboardInterrupt:
print("Training stopped.")
finally:
print(f"Best valid loss: {best_loss}")
self.clf.load_state_dict(torch.load(tmp.name))
return history
def lf_outputs(self, x):
L = torch.stack([lf(x) for lf in self.lfs], dim=1).long()
return L
@torch.no_grad()
def predict_proba(self, x):
s = self.clf(x).view(-1)
return 1 / (1 + torch.exp(-s))
@torch.no_grad()
def predict(self, x, t=0.0):
s = self.clf(x).view(-1)
return 2 * (s > t).long() - 1
clf = nn.Sequential(nn.Linear(2, 8), nn.SELU(), nn.Linear(8, 1))
trainer = NoiseAwareTrainer(clf, gen_model, labeling_funcs=labeling_funcs)
history = trainer.run(x_train, x_valid, epochs=120, bs=32, lr=0.003, alpha=0.0, momentum=0.1)
Best valid loss: 0.34659144282341003
Show code cell source
plt.plot(history["train"], label="train")
plt.plot(history["valid_steps"], history["valid"], label="valid")
plt.ylabel("loss")
plt.xlabel("step")
plt.legend();

print(evaluate(trainer, x_train, y_train, t=0.0)["message"]); print()
print(evaluate(trainer, x_valid, y_valid, t=0.0)["message"])
[[3172 0]
[1008 3820]]
m=8000, f1=0.87529
[[820 0]
[243 937]]
m=2000, f1=0.87937
The threshold for predicting hard labels can be calibrated by using the prior label distribution. This significantly improves F1. Here we use the entirety of our data (i.e. x):
from collections import Counter
calibration_score = [] # lower = better
thresholds = np.linspace(-1, 1, num=500)
for t in thresholds:
c = Counter(trainer.predict(x, t).tolist())
n = len(x)
c[-1] = c[-1] / n
c[+1] = c[+1] / n
calibration_score.append(-LABEL_PROBS[-1] * np.log(c[-1]) + -LABEL_PROBS[+1] * np.log(c[+1]))
t_best = thresholds[np.argmin(calibration_score)]
print(evaluate(trainer, x_train, y_train, t=t_best)["message"]); print()
print(evaluate(trainer, x_valid, y_valid, t=t_best)["message"])
[[2615 557]
[ 293 4535]]
m=8000, f1=0.89286
[[ 698 122]
[ 70 1110]]
m=2000, f1=0.90346
If we have a small labeled subset of the data, then we can use that to tune the threshold. The following iteratively finds the threshold that maximizes weighted F1 on the validation set:
def pr_curve(model, x, y, num_thresholds, min_t=-1.0, max_t=1.0):
p, r, t, f = [], [], [], []
for threshold in np.linspace(min_t, max_t, num_thresholds):
preds = model.predict(x, threshold).numpy()
f.append(f1_score(y.numpy(), preds, average="weighted"))
r.append(recall_score(y.numpy(), preds, average="weighted"))
p.append(precision_score(y.numpy(), preds, average="weighted"))
t.append(threshold)
return p, r, t, f
def plot_pr_curve(model, x_valid, y_valid, num_thresholds=200, min_t=-1.0, max_t=1.0):
"""Tune threshold based on validation set."""
p, r, t, f = pr_curve(model, x_valid, y_valid, num_thresholds, min_t, max_t);
t_best_ = np.argmax(f)
t_best = t[t_best_]
# plotting the sample F1s
plt.grid(linestyle="dotted", zorder=0)
plt.scatter(r, p, c=f, zorder=2)
plt.scatter(x=r[t_best_], y=p[t_best_], edgecolor="k", facecolor="red", label=f"best F1={f[t_best_]:.3f}, t={t_best:.3f}", zorder=3)
plt.colorbar()
plt.xlabel("recall")
plt.ylabel("precision")
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.legend(loc="lower right")
return t_best
# Fine tuning the threshold on small labeled data (i.e. x_valid):
t_best = plot_pr_curve(trainer, x_valid, y_valid, num_thresholds=500, min_t=-1.0, max_t=1.0)
print(evaluate(trainer, x_train, y_train, t=t_best)["message"]); print()
print(evaluate(trainer, x_valid, y_valid, t=t_best)["message"])
[[3172 0]
[ 380 4448]]
m=8000, f1=0.95287
[[ 819 1]
[ 97 1083]]
m=2000, f1=0.95132

Remark. Model has learned fairly well despite having suboptimal LFs.
■