
$ ok-transformer --help
Exploring machine learning engineering and operations. ❚
![]()


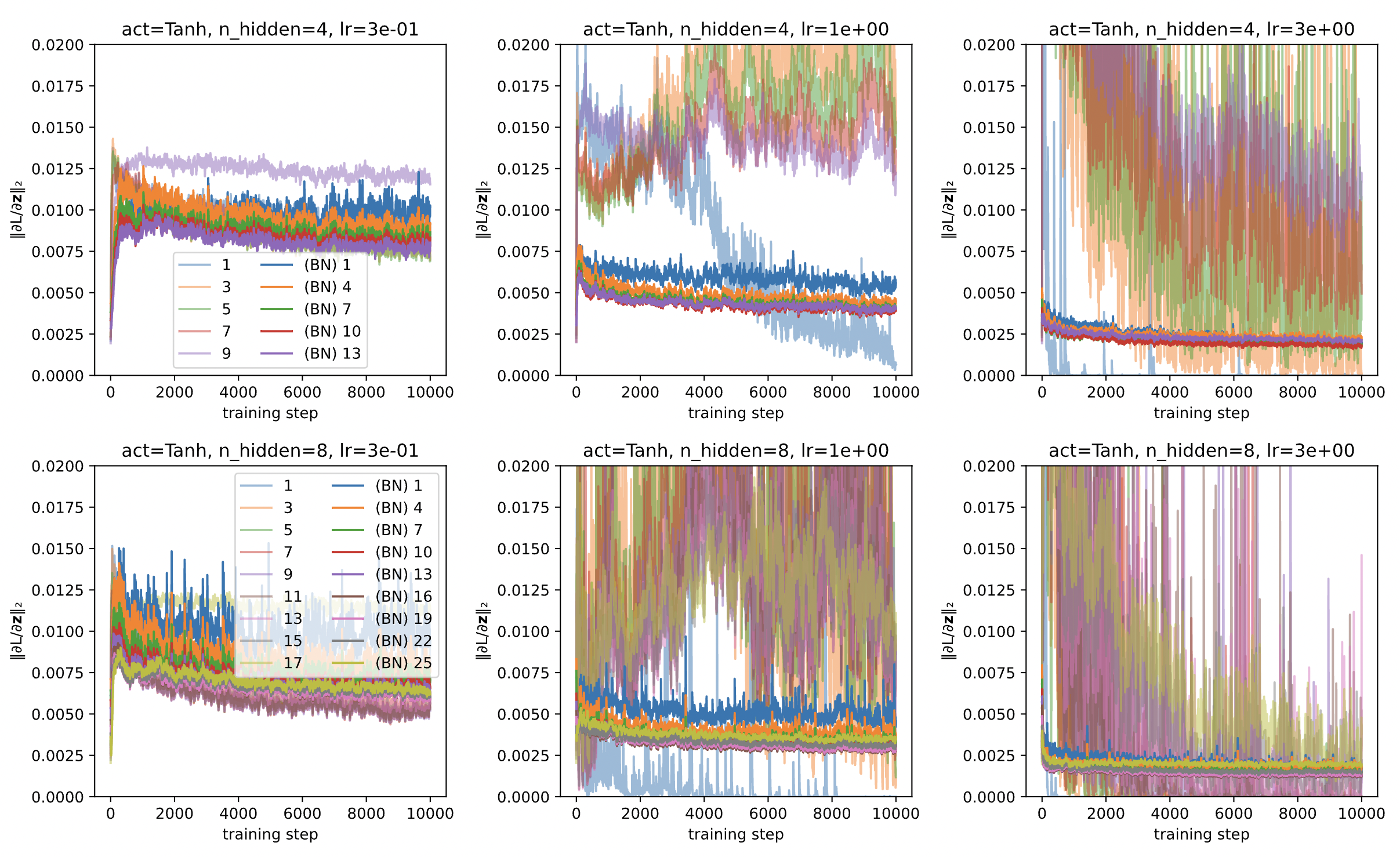
Fig. 1 Effect of batch normalization on the magnitude of preactivation gradients.
Frameworks

Hardware
Component |
Kaggle Notebook |
MacBook Air M1 |
|---|---|---|
GPU 0 |
Tesla P100-PCIE-16GB |
Apple M1 Integrated GPU |
CPU |
Intel Xeon CPU @ 2.00GHz |
Apple M1 8-core CPU |
Core |
1 |
4 high-performance, 4 efficiency |
Threads per core |
2 |
1 |
L3 Cache |
38.5 MiB |
12 MiB |
Memory |
15 GB |
8 GB Unified Memory |
References
A. R. Barron. Approximation and estimation bounds for artificial neural networks. In Proceedings of the Fourth Annual Workshop on Computational Learning Theory, COLT '91, 243–249. San Francisco, CA, USA, 1991. Morgan Kaufmann Publishers Inc.
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Janvin. A neural probabilistic language model. J. Mach. Learn. Res., 3:1137–1155, March 2003. URL: http://dl.acm.org/citation.cfm?id=944919.944966.
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. CoRR, 2014. URL: http://arxiv.org/abs/1406.1078, arXiv:1406.1078.
François Chollet. Deep Learning with Python, Second Edition. Manning, 2021. ISBN 9781617296864.
Anna Choromanska, MIkael Henaff, Michael Mathieu, Gerard Ben Arous, and Yann LeCun. The Loss Surfaces of Multilayer Networks. In Guy Lebanon and S. V. N. Vishwanathan, editors, Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, volume 38 of Proceedings of Machine Learning Research, 192–204. San Diego, California, USA, 09–12 May 2015. PMLR. URL: https://proceedings.mlr.press/v38/choromanska15.html.
Yann N. Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS'14, 2933–2941. Cambridge, MA, USA, 2014. MIT Press.
Aurélien Géron. Hands-on machine learning with Scikit-Learn and TensorFlow : concepts, tools, and techniques to build intelligent systems, Second Edition. O'Reilly Media, Sebastopol, CA, 2019. ISBN 978-1491962299.
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: training imagenet in 1 hour. 2017. URL: https://arxiv.org/abs/1706.02677, doi:10.48550/ARXIV.1706.02677.
Diego Granziol, Stefan Zohren, and Stephen Roberts. Learning rates as a function of batch size: a random matrix theory approach to neural network training. 2021. arXiv:2006.09092.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, 2015. URL: http://arxiv.org/abs/1512.03385, arXiv:1512.03385.
Geoffrey Hinton. Neural networks for machine learning: lecture 6a overview of mini-batch gradient descent. Lecture Slides, Coursera, 2012. Accessed: 2024-08-28. URL: http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf.
Sepp Hochreiter and Jürgen Schmidhuber. Flat minima. Neural Computation, 9(1):1–42, 1997. doi:10.1162/neco.1997.9.1.1.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997. doi:10.1162/neco.1997.9.8.1735.
Gao Huang, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E. Hopcroft, and Kilian Q. Weinberger. Snapshot ensembles: train 1, get M for free. CoRR, 2017. URL: http://arxiv.org/abs/1704.00109, arXiv:1704.00109.
Sergey Ioffe and Christian Szegedy. Batch normalization: accelerating deep network training by reducing internal covariate shift. CoRR, 2015. URL: http://arxiv.org/abs/1502.03167, arXiv:1502.03167.
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: generalization gap and sharp minima. CoRR, 2016. URL: http://arxiv.org/abs/1609.04836, arXiv:1609.04836.
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: generalization gap and sharp minima. CoRR, 2016. URL: http://arxiv.org/abs/1609.04836, arXiv:1609.04836.
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. 2015. URL: http://arxiv.org/abs/1412.6980.
Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. Self-normalizing neural networks. CoRR, 2017. URL: http://arxiv.org/abs/1706.02515, arXiv:1706.02515.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012. URL: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. In Proceedings of the IEEE, volume 86, 2278–2324. 1998. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.42.7665.
Hao Li, Zheng Xu, Gavin Taylor, and Tom Goldstein. Visualizing the loss landscape of neural nets. CoRR, 2017. URL: http://arxiv.org/abs/1712.09913, arXiv:1712.09913.
Zehui Lin, Pengfei Liu, Luyao Huang, Junkun Chen, Xipeng Qiu, and Xuanjing Huang. Dropattention: A regularization method for fully-connected self-attention networks. CoRR, 2019. URL: http://arxiv.org/abs/1907.11065, arXiv:1907.11065.
Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with restarts. CoRR, 2016. URL: http://arxiv.org/abs/1608.03983, arXiv:1608.03983.
Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. CoRR, 2017. URL: http://arxiv.org/abs/1711.05101, arXiv:1711.05101.
Dominic Masters and Carlo Luschi. Revisiting small batch training for deep neural networks. CoRR, 2018. URL: http://arxiv.org/abs/1804.07612, arXiv:1804.07612.
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: where bigger models and more data hurt. CoRR, 2019. URL: http://arxiv.org/abs/1912.02292, arXiv:1912.02292.
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: attention with linear biases enables input length extrapolation. 2022. arXiv:2108.12409.
S. Raschka, Y. Liu, V. Mirjalili, and D. Dzhulgakov. Machine Learning with PyTorch and Scikit-Learn: Develop Machine Learning and Deep Learning Models with Python. Expert insight. Packt Publishing, 2022. ISBN 9781801819312. URL: https://books.google.com.ph/books?id=UHbNzgEACAAJ.
Alexander Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, and Christopher Ré. Data programming: creating large training sets, quickly. 2017. arXiv:1605.07723.
M. Schuster and K.K. Paliwal. Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11):2673–2681, 1997. doi:10.1109/78.650093.
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, 2014. URL: http://arxiv.org/abs/1409.1556.
Leslie N. Smith and Nicholay Topin. Super-convergence: very fast training of residual networks using large learning rates. CoRR, 2017. URL: http://arxiv.org/abs/1708.07120, arXiv:1708.07120.
Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller. Striving for simplicity: the all convolutional net. 2014. URL: https://arxiv.org/abs/1412.6806, doi:10.48550/ARXIV.1412.6806.
Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1):1929–1958, 2014. URL: http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf.
Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. CoRR, 2016. URL: http://arxiv.org/abs/1609.03499, arXiv:1609.03499.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. CoRR, 2017. URL: http://arxiv.org/abs/1706.03762, arXiv:1706.03762.
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. CoRR, 2020. URL: https://arxiv.org/abs/2002.04745, arXiv:2002.04745.
Pan Zhou, Jiashi Feng, Chao Ma, Caiming Xiong, Steven Hoi, and E. Weinan. Towards theoretically understanding why sgd generalizes better than adam in deep learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS'20. Red Hook, NY, USA, 2020. Curran Associates Inc.