Introduction to Neural Networks
Deep learning models are machine learning models with multiple layers of learned representations. A layer refers to any transformation that maps an input to its feature representation. In principle, any function that can be described as a composition of layers with differentiable operations is called a neural network. Representations are powerful. In machine translation, sentences are not translated word-for-word between two languages. Instead, a model learns an intermediate representation that captures the ‘thought’ shared by the translated sentences (Fig. 2).
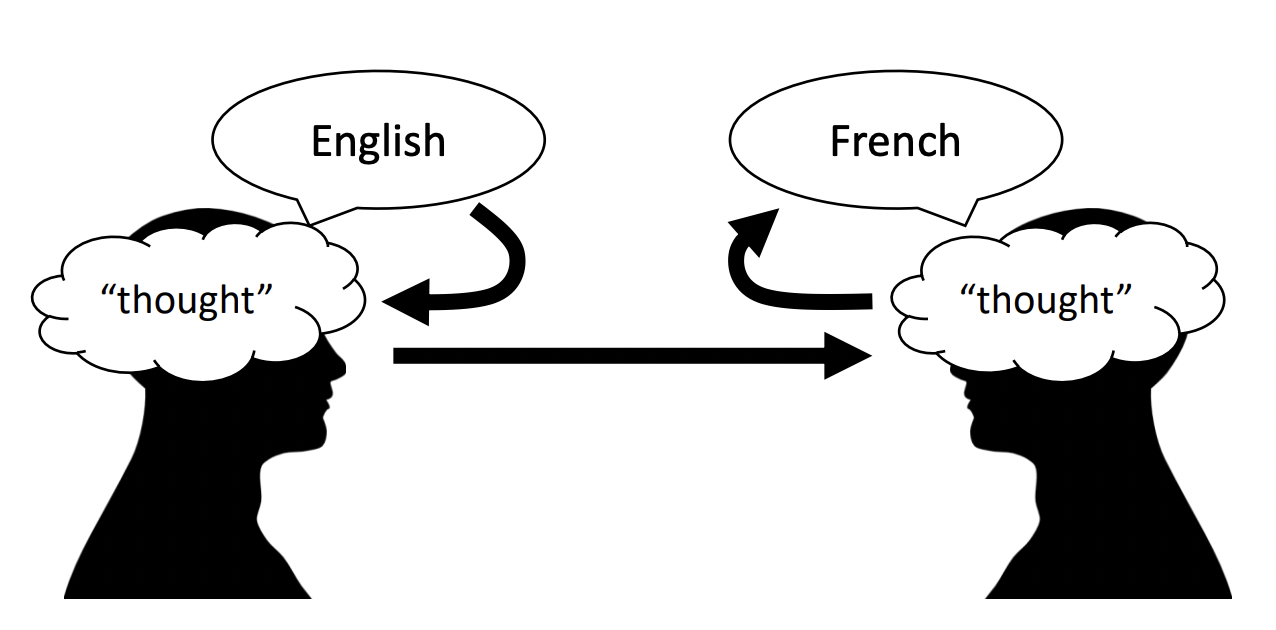
Fig. 2 Thought is a representation.
The practical successes of deep learning can be attributed to three factors:
Scalability. Deep neural networks (Fig. 3) are created by stacking multiple layers (10-100+). Features at deep layers can be thought of as combinatorial, higher-level, and less sensitive to noise, thereby improving generalization. On the other hand, wider layers, i.e. layers with more parameters, memorizes features better at that level. There are tradeoffs with depth and width that has to be controlled in order to get effectively sized networks. But in general, the larger the network, the better it generalizes to test data (Fig. 4).
Massive datasets. Deep large networks (Fig. 3) are necessary for tasks involving massive, complex, structured datasets like images and text, where the complexity of the model aligns with that of the underlying distributions in the data. Moreover, complex models allow for automatic feature engineering, provided that prior knowledge about the structure (or modality) of the data is encoded into the network architecture. Another interesting property of neural networks is that knowledge can be transferred between tasks through transfer learning where are a large model pre-trained on a large dataset can be adapted to specialized tasks using smaller datasets.
Compute. Both of these factors require significant computational resources (Fig. 4). GPUs are particularly well-suited for the large scale matrix operations required in deep learning with their parallel processing capabilities.
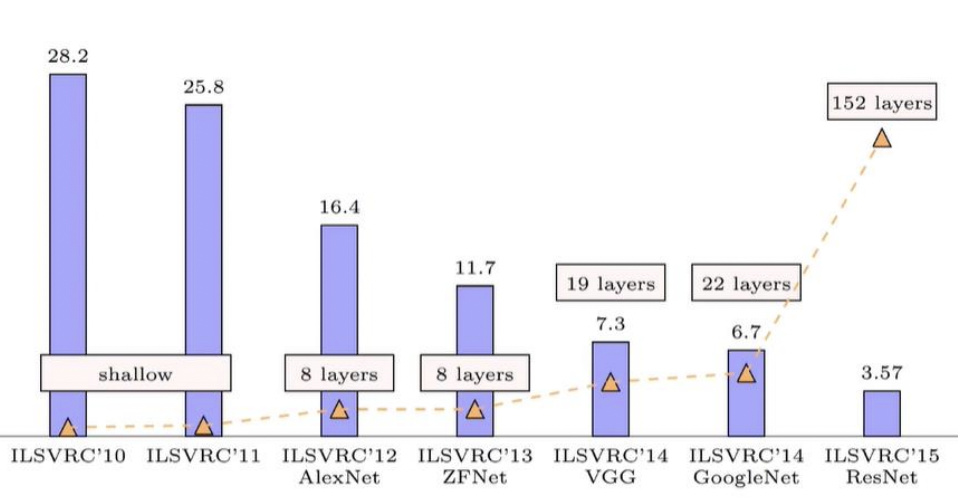
Fig. 3 Progress in top-5 error in the ImageNet competition.
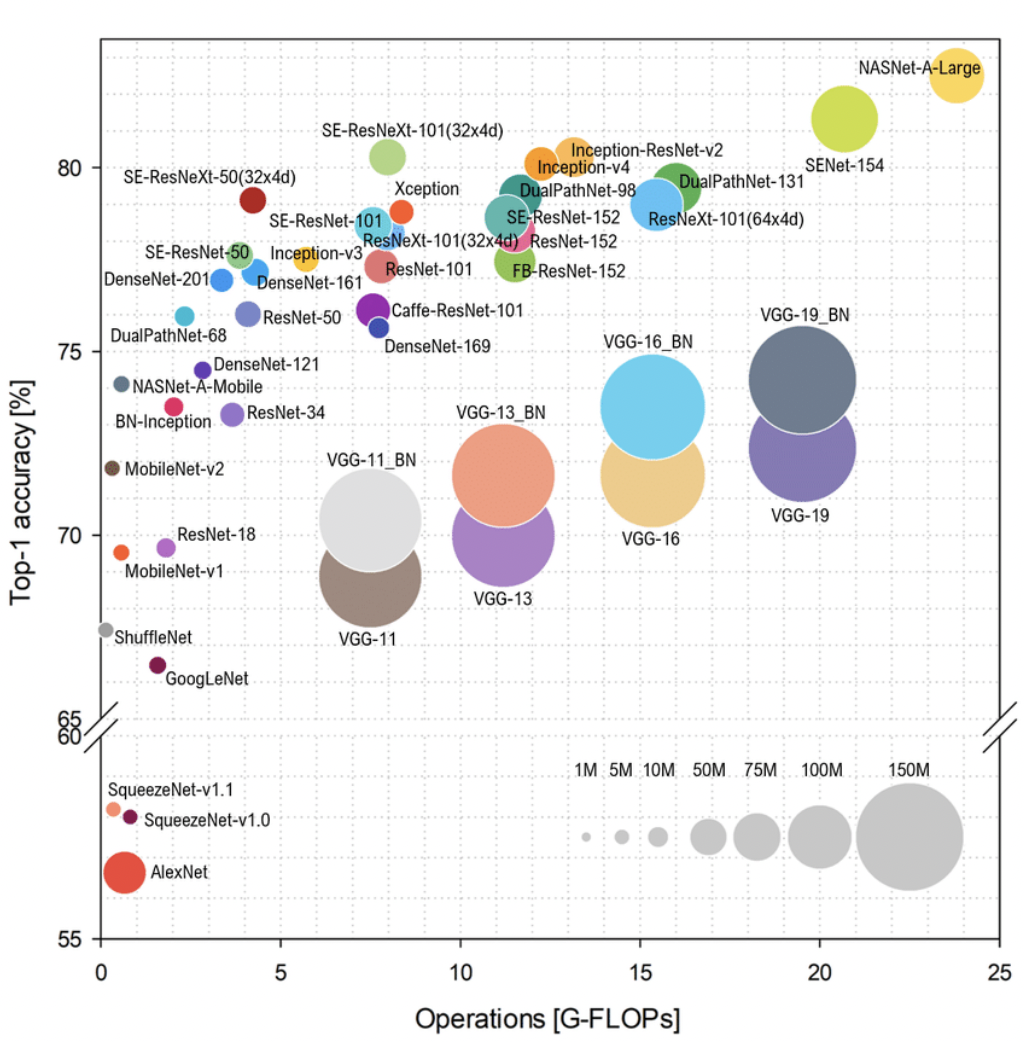
Fig. 4 Top-1 accuracy vs GFLOPs on ImageNet. Performance generally improve with increasing compute. But some architectures such as ResNet have better tradeoff than others, e.g. VGG.