Text generation
Recall that the state vector is initialized as zero. So we use a warmup context or a prompt to allow the RNN cell to update its state iteratively by processing one character at a time from the warmup text. Then, the algorithm simulates the prediction process of our RNN language model, but instead of using a predefined input sequence, it uses the previous output as the next input.
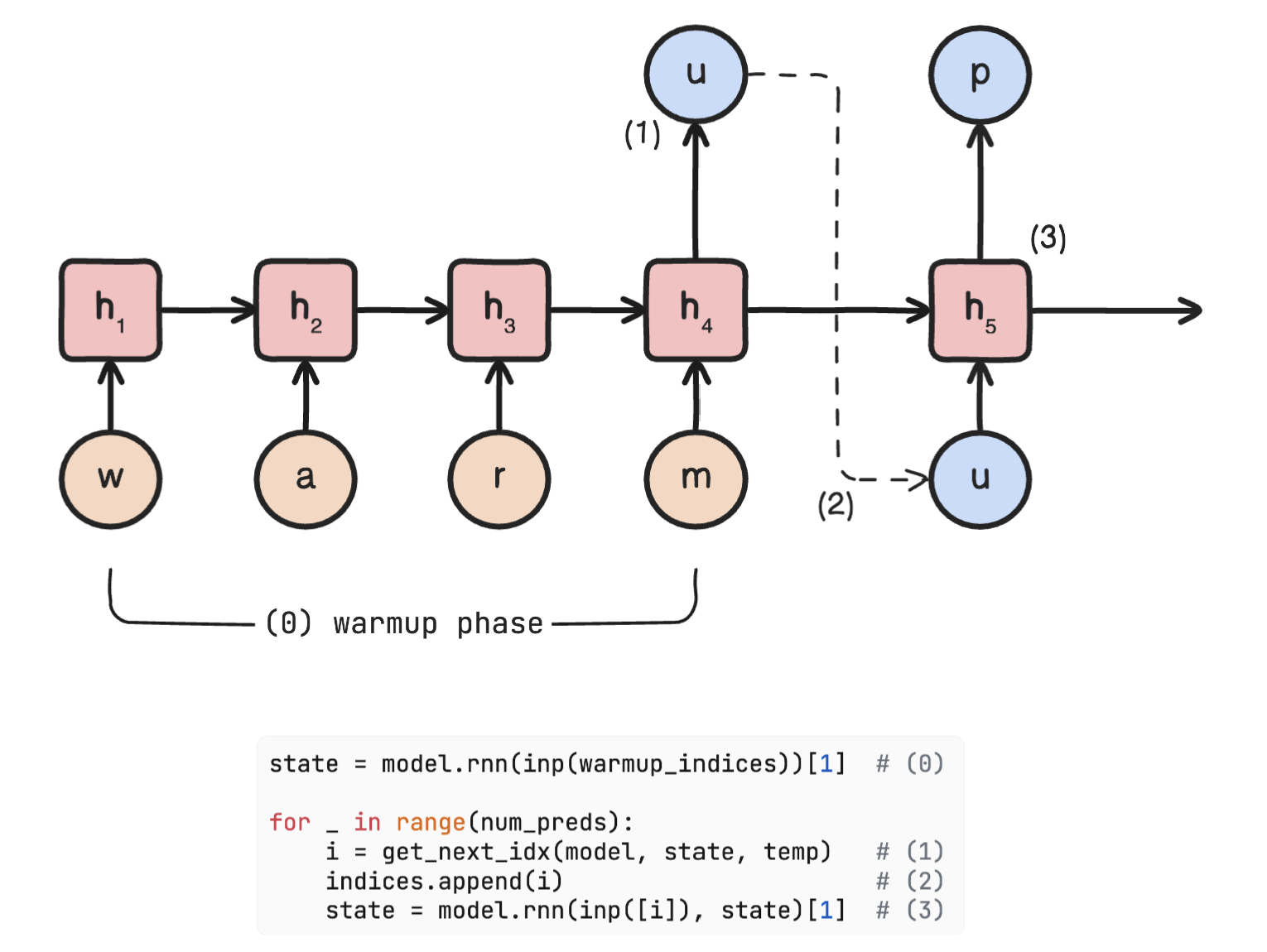
Fig. 58 An input sequence is used to get a final state vector (this is the warmup stage, i.e. the state goes from zero to some nonzero vector). The final character and state during warmup is used to predict the next character. This process is repeated until the number of predicted tokens is reached.
Loading the trained RNN language model:
DEVICE = "cpu" # faster for RNN inference
WEIGHTS_PATH = "./artifacts/rnn_lm.pkl"
data, tokenizer = TimeMachine().build()
VOCAB_SIZE = tokenizer.vocab_size
model = LanguageModel(RNN)(VOCAB_SIZE, 64, VOCAB_SIZE)
model.load_state_dict(torch.load(WEIGHTS_PATH, map_location=DEVICE));
Text generation utils and algorithm:
import torch
import torch.nn.functional as F
class TextGenerator:
def __init__(self, model, tokenizer, device="cpu"):
self.model = model.to(device)
self.device = device
self.tokenizer = tokenizer
def _inp(self, indices: list[int]):
"""Preprocess indices (T,) to (T, 1, V) shape with B=1."""
VOCAB_SIZE = self.tokenizer.vocab_size
x = F.one_hot(torch.tensor(indices), VOCAB_SIZE).float()
return x.view(-1, 1, VOCAB_SIZE).to(self.device)
@staticmethod
def sample_token(logits, temperature: float):
"""Convert logits to probs with softmax temperature."""
p = F.softmax(logits / temperature, dim=1) # T = ∞ => exp ~ 1 => p ~ U[0, 1]
return torch.multinomial(p, num_samples=1).item()
def predict(self, prompt: str, num_preds: int, temperature=1.0):
"""Simulate character generation one at a time."""
# Iterate over warmup text. RNN cell outputs final state
warmup_indices = self.tokenizer.encode(prompt.lower()).tolist()
outs, state = self.model(self._inp(warmup_indices), return_state=True)
# Sample next token and update state
indices = []
for _ in range(num_preds):
i = self.sample_token(outs[-1], temperature)
indices.append(i)
outs, state = self.model(self._inp([i]), state, return_state=True)
return self.tokenizer.decode(warmup_indices + indices)
Sanity test. Completing ‘thank you’:
textgen = TextGenerator(model, tokenizer, device="cpu")
s = [textgen.predict("thank y", num_preds=2, temperature=0.4) for i in range(20)]
(np.array(s) == "thank you").mean()
0.9
Example. The network can generate output given warmup prompt of arbitrary length. Here we also look at the effect of temperature on the generated text:
warmup = "mr williams i underst"
text = []
temperature = []
for i in range(1, 6):
t = 0.20 * i
s = textgen.predict(warmup, num_preds=100, temperature=t)
text.append(s)
temperature.append(t)
Show code cell source
from IPython.display import display
import pandas as pd
pd.set_option("display.max_colwidth", None)
df = pd.DataFrame({"temp": [f"{t:.1f}" for t in temperature], "text": text})
df = df.style.set_properties(**{"text-align": "left"})
display(df)
| temp | text | |
|---|---|---|
| 0 | 0.2 | mr williams i underst in the thing in the morlocks and the the the machine and the strange and the morlocks of the the th |
| 1 | 0.4 | mr williams i understed a strange the from the limporle i was and and i had into my our in the morlocks of the machine th |
| 2 | 0.6 | mr williams i underst and she of the fire and myself in the morlocks on a cliltion and i saw the mame on a great the out |
| 3 | 0.8 | mr williams i understoo to and to durken the fast and shaps of find prestain into the medied and frrances to the excheti |
| 4 | 1.0 | mr williams i understolfurully the sakent way and white to minute screal side cleading in the noffst most i ranntly of th |
The generated text appear more random as we increase the sampling temperature[1]. Conversely, as the temperature decreases, the softmax function behaves more like an argmax. In this scenario, the sampling algorithm selects the token with the highest probability, which increases the likelihood of cycles.